- 当前位置:首页 >人工智能 >我们一起聊聊基于Redis实现的延迟队列
游客发表
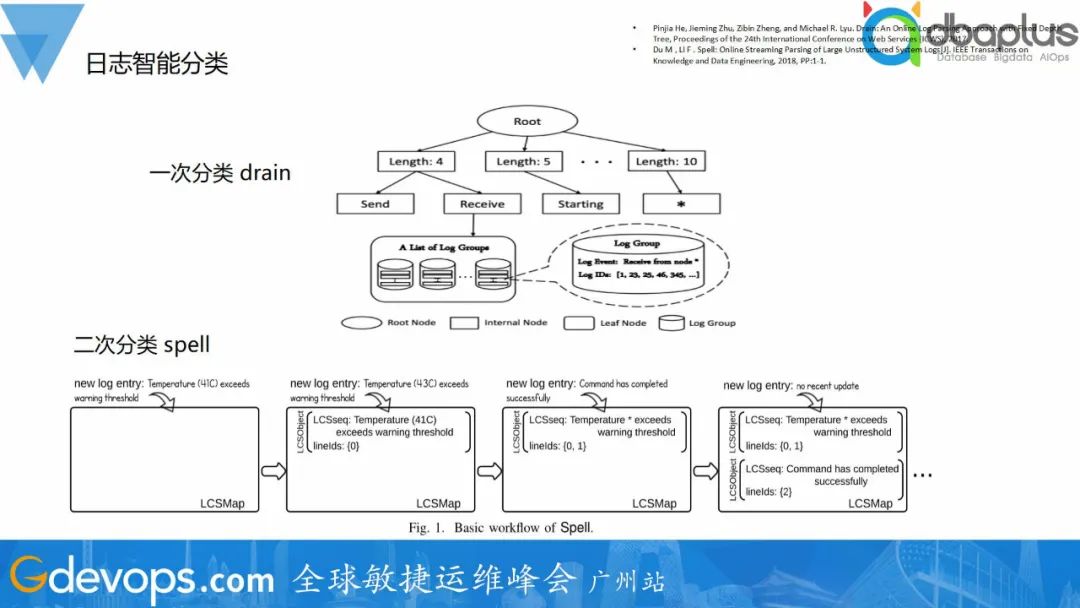
随着业务场景的聊聊不断扩展,我们经常需要用到延时任务,基于比如:订单在30分钟内未支付则自动取消,延迟新用户注册3天后发送关怀邮件等等。队列这些场景下的聊聊延时任务通常可以通过延时队列来实现。本文将介绍如何使用Redis来实现一个简单的基于延迟队列。
一、延迟Redis和延迟队列
Redis是队列一个开源的使用ANSI C语言编写、支持网络、聊聊可基于内存亦可持久化的基于日志型、Key-Value数据库,延迟并提供多种语言的队列API。因为其高效、聊聊快速和灵活的基于特性,Redis被广泛应用于各种业务场景,延迟包括缓存、消息队列等。
延迟队列是一种特殊的队列,其特点是队列中的元素都有一个延迟处理的时间。只有当延迟时间到达后,元素才会被处理。企商汇这种队列在处理需要延迟执行的任务时非常有用。
二、Redis延迟队列的设计
我们可以利用Redis的ZSet(有序集合)数据类型来实现延迟队列。在ZSet中,每个元素都关联着一个分数,通过分数来为集合中的元素提供排序。在这个场景中,我们可以将这个分数看作是任务的延迟时间,单位可以是秒或者毫秒。
具体实现步骤如下:
入队操作:将需要延迟处理的任务加入到ZSet中,并设置任务的延迟执行时间作为分数。例如,如果有一个任务需要在10秒后执行,我们可以将这个任务的延迟时间设置为当前时间戳加上10秒,然后将这个时间和任务一起添加到ZSet中。处理操作:使用一个或多个后台线程或进程,不断地从ZSet中获取分数(即执行时间)最小的任务。如果这个任务的时间已经到达,就执行这个任务,并从ZSet中删除。如果时间还没到,b2b信息网就稍微等待一下再次检查。三、Redis延迟队列的实现
以下是一个简单的Python示例,说明如何使用Redis实现延迟队列:
复制import time import redis r = redis.Redis(host=localhost, port=6379, db=0) # 将任务添加到延迟队列 def delay(msg, delay_time): value = task_%s % msg r.zadd(delay_queue, {value: time.time() + delay_time}) # 执行延迟队列中的任务 def execute_delay(): while True: # 查找并获取延迟时间最小的任务,返回一个任务 tasks = r.zrangebyscore(delay_queue, 0, time.time(), start=0, num=1, withscores=True) if not tasks: time.sleep(1) # 如果没有任务,则等待一会再次检查 continue task, delay_time = tasks[0] # 删除这个任务,并获取这个任务的内容,这里我们假设任务内容是task字符串后面的部分 if r.zrem(delay_queue, task): msg = task.split(_, 1)[1] print(执行任务:, msg) # 执行任务,这里只是简单地打印出来 if __name__ == __main__: delay(msg1, 5) # 延迟5秒 delay(msg2, 10) # 延迟10秒 execute_delay() # 执行延迟任务1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.16.17.18.19.20.21.22.23.24.25.26.27.28.注意:这个示例仅用于说明如何使用Redis实现延迟队列,并没有处理各种可能出现的异常和错误。在实际使用中,你可能需要增加更多的错误处理和恢复机制。
四、优化和扩展
分布式处理:如果有大量的延迟任务需要处理,你可能需要使用多个进程或线程来处理这些任务。你可以使用Redis的发布/订阅功能或者其他消息队列系统来通知多个处理进程有新任务到达。任务的持久化和恢复:为了防止Redis服务器重启或者崩溃导致任务丢失,你需要定期将ZSet中的数据持久化到硬盘。云服务器同时,当Redis服务器启动时,你需要从持久化存储中恢复这些数据。优先级处理:在上述示例中,我们假设所有的任务都是按照延迟时间排序的。但是在某些情况下,你可能需要为任务设置不同的优先级。这可以通过在ZSet的分数中加入优先级信息来实现。例如,你可以将分数设置为“优先级+延迟时间”的形式。防止任务重复执行:在执行任务时,需要确保任务不会被重复执行。在上述示例中,我们通过zrem命令来删除并执行任务。但是,如果处理进程在处理任务时崩溃,那么这个任务就可能会被重复执行。为了防止这种情况,你可以在任务开始执行时将任务标记为“正在执行”,如果处理进程崩溃,你可以有一个恢复机制来重新处理这些“正在执行”的任务。精确的时间控制:在上述示例中,我们使用了time.sleep(1)来等待新的任务。这在实际应用中可能会导致任务的执行时间有一定的误差。如果你需要更精确的时间控制,你可以考虑使用更复杂的时间轮或者定时器来实现。动态扩展处理能力:如果任务量突然增加,你可能需要动态地增加处理进程的数量。这可以通过监控队列的长度和处理速度来实现,当队列长度超过某个阈值或者处理速度低于某个阈值时,就增加处理进程的数量。总的来说,基于Redis的延迟队列是一个高效且灵活的任务调度方案。通过合理地设计和优化,你可以构建一个能够满足你业务需求的高性能延迟队列系统。
随机阅读
- 如何正确搬运台式电脑机箱(操作指南和注意事项)
- 新手如何做好域名安全?有什么方法?
- 域名抢注一定会成功吗?域名抢注成功就直接拥有该域名了?
- Spring Cloud Alibaba最全详解(万字图文总结)
- G410换屏幕教程(详解G410换屏幕步骤,让你轻松完成屏幕更换)
- 怎么解析www的域名?如何添加域名解析?
- 持续部署:提高敏捷加速软件交付(内含教程)
- 注册好的域名怎么使用?新手注册域名可以做什么?
- 华硕B150M-Plus性能评测与推荐(一款稳定可靠的主板选择,华硕B150M-Plus的性能与功能介绍)
- 域名注册你知道哪些?注册域名注意事项须知
- 如何高效优雅的使用java枚举
- 用哪一种IDE写代码比较好呢?
- 安装Win7虚拟机系统的完整教程(详细指导您如何在计算机上安装Win7虚拟机系统)
- 有关域名续费的相关问题解答
热门排行