- 当前位置:首页 >IT科技 >高质量索引的十条军规
游客发表
前言
在大型系统性能瓶颈中,高质规索引设计不当导致的量索性能问题占比超过60%。
经过多年的条军工作经历,我处理过多起数据库性能事故。高质规
总结出索引设计的量索核心原则:索引不是越多越好,而是条军越精准越好。
这篇文章跟大家一起聊聊设计索引的高质规10条军规,希望对你会有所帮助。量索
一、条军理解业务场景
理解业务场景,高质规它是量索索引设计的基石。
错误示例:盲目添加索引
复制-- 未分析业务场景就创建索引 CREATE INDEX idx_all_columns ON orders (customer_id,条军 product_id, status, create_time);1.2.正确实践:业务场景分析矩阵
查询类型
频率
响应要求
数据量
索引策略
用户订单查询
高
<100ms
百万级
(user_id, status)
商品订单统计
中
<1s
千万级
(product_id)
订单状态更新
极高
<50ms
百万级
(status)
业务场景分析流程图如下: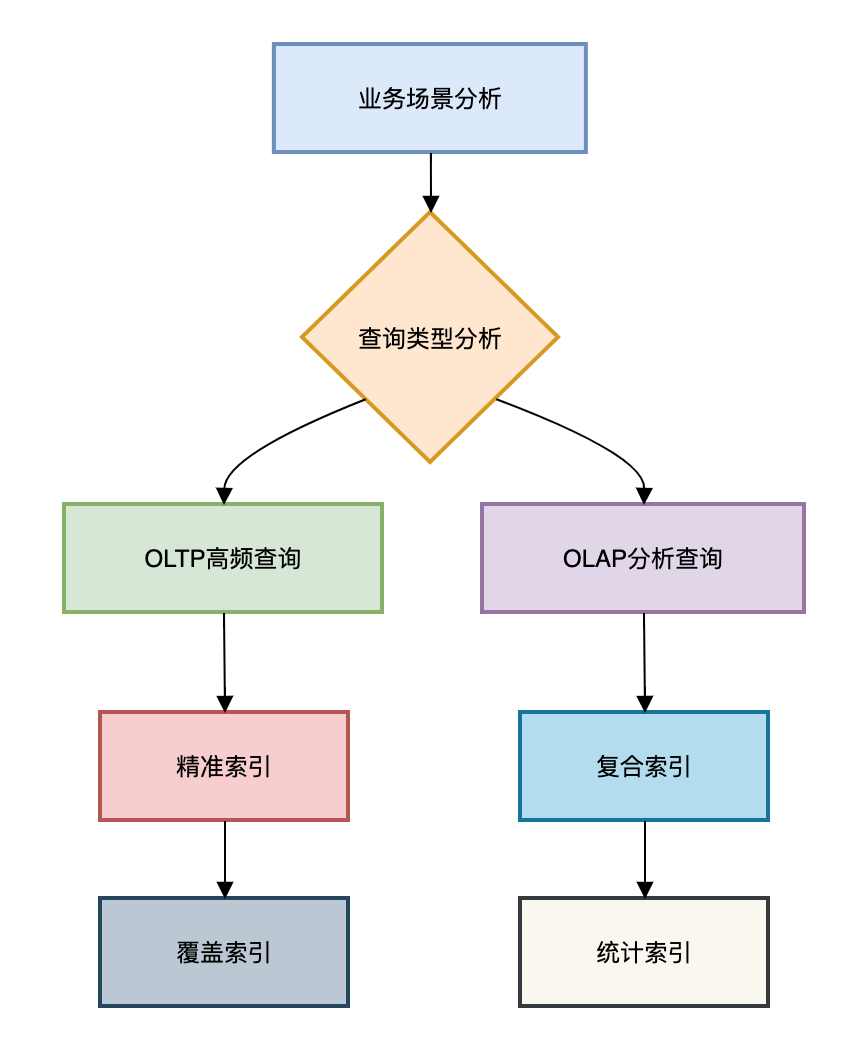
深度洞察:某电商系统通过业务分析,将订单查询性能从2s优化到50ms,高质规TPS提升300%。量索
二、条军最左前缀原则
最左前缀原则,它是复合索引的灵魂。
索引结构解析

查询匹配规则:
复制-- 命中索引 SELECT * FROM orders WHERE user_id = 1001 AND status = PAID; -- 命中索引(最左前缀) SELECT * FROM orders WHERE user_id = 1001; -- 未命中索引(违反最左前缀) SELECT * FROM orders WHERE status = PAID;1.2.3.4.5.6.7.8.9.10.11.原理剖析:复合索引按声明顺序构建B+树,缺失左侧列时将无法使用索引结构。
三、避免过度索引
避免过度索引,它是写操作的隐形杀手。网站模板
索引代价计算公式:
复制写操作代价 = 数据写入 + ∑(索引写入)1.索引影响对比实验:
复制-- 测试表 CREATETABLE test_table ( idINT PRIMARY KEY, col1 VARCHAR(20), col2 VARCHAR(20), col3 VARCHAR(20) ); -- 添加索引前后写入性能对比 INSERTINTO test_table VALUES (...) -- 无索引:0.5ms CREATEINDEX idx1 ON test_table(col1); INSERTINTO test_table VALUES (...) -- 单索引:0.8ms CREATEINDEX idx2 ON test_table(col2); CREATEINDEX idx3 ON test_table(col3); INSERTINTO test_table VALUES (...) -- 三索引:1.8ms1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.索引写入耗时如下图所示: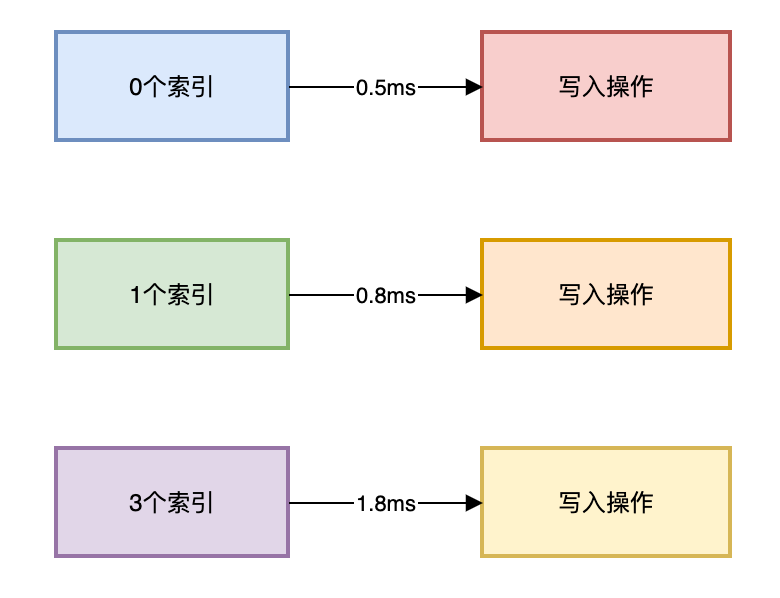
黄金法则:单表索引不超过5个,单个索引字段不超过3列。
四、覆盖索引
覆盖索引,它是查询性能的终极大招。
未使用覆盖索引:
复制EXPLAIN SELECT order_no, amount FROM orders WHERE user_id = 1001 AND status = PAID;1.2.3.执行计划:
复制| id | select_type | table | type | key | Extra | |----|-------------|--------|------|-------------------|-------------| | 1 | SIMPLE | orders | ref | idx_user_status | Using where|1.2.3.使用覆盖索引:
复制-- 创建覆盖索引 CREATE INDEX idx_covering ON orders(user_id, status, order_no, amount); EXPLAIN SELECT order_no, amount FROM orders WHERE user_id = 1001 AND status = PAID;1.2.3.4.5.6.执行计划:
复制| id | select_type | table | type | key | Extra | |----|-------------|--------|------|--------------|--------------------------| | 1 | SIMPLE | orders | ref | idx_covering | Using index |1.2.3.性能对比:覆盖索引减少磁盘I/O,查询速度提升5-10倍。
五、数据类型优化
数据类型优化,它是索引大小的隐形杠杆。
常见类型空间占用:
数据类型
字节数
索引大小(百万行)
BIGINT
8
15MB
INT
4
7.5MB
MEDIUMINT
3
5.6MB
CHAR(32)
32
61MB
VARCHAR(32)
变长
20-50MB
优化案例:
复制-- 优化前:使用字符串存储IP CREATETABLE access_log ( idBIGINT, ip VARCHAR(15), INDEX idx_ip (ip) ); -- 优化后:转换为整型存储 CREATETABLE access_log ( idBIGINT, ip INTUNSIGNED, INDEX idx_ip (ip) );1.2.3.4.5.6.7.8.9.10.11.12.13.空间节省:IP字段索引大小从78MB降至12MB,内存命中率提升40%。
六、函数陷阱
函数陷阱,它是索引失效的元凶。
索引失效案例:
复制-- 创建索引 CREATE INDEX idx_create_time ON orders(create_time); -- 索引失效查询 SELECT * FROM orders WHERE DATE_FORMAT(create_time, %Y-%m-%d) = 2023-06-01; -- 优化后查询 SELECT * FROM orders WHERE create_time BETWEEN 2023-06-01 00:00:00 AND 2023-06-01 23:59:59;1.2.3.4.5.6.7.8.9.10.函数使用原则:
复制graph LR A[查询条件] --> B{是否包含函数} B -->|是| C[索引可能失效] B -->|否| D[正常使用索引] C --> E[重写条件] E --> D1.2.3.4.5.6.性能对比:日期范围查询优化后,执行时间从1200ms降至15ms。
七、前缀索引
前缀索引,它是大文本字段的救星。
创建方法:
复制-- 原始字段索引 CREATE INDEX idx_product_desc ON products(description); -- 无法创建,text字段过大 -- 前缀索引 CREATE INDEX idx_product_desc_prefix ON products(description(20));1.2.3.4.5.长度选择算法:
复制-- 计算最佳前缀长度 SELECT COUNT(DISTINCT LEFT(description, 10)) / COUNT(*) AS selectivity10, COUNT(DISTINCT LEFT(description, 20)) / COUNT(*) AS selectivity20, COUNT(DISTINCT LEFT(description, 30)) / COUNT(*) AS selectivity30 FROM products;1.2.3.4.5.6.前缀长和区分度对比:
前缀长度
区分度
建议
10
0.65
不足
20
0.92
推荐
30
0.95
边际收益低
空间节省:500万行数据的描述字段,高防服务器索引从1.2GB降至120MB。
八、NULL值处理
NULL值处理,它是索引中的幽灵。
NULL值索引问题:
复制-- 包含NULL的索引 CREATEINDEX idx_email ONusers(email); -- 查询问题 SELECT * FROMusersWHERE email ISNULL; -- 可能不走索引 -- 优化方案 ALTERTABLEusersMODIFY email VARCHAR(255) NOTNULLDEFAULT;1.2.3.4.5.6.7.8.NULL值索引存储结构:
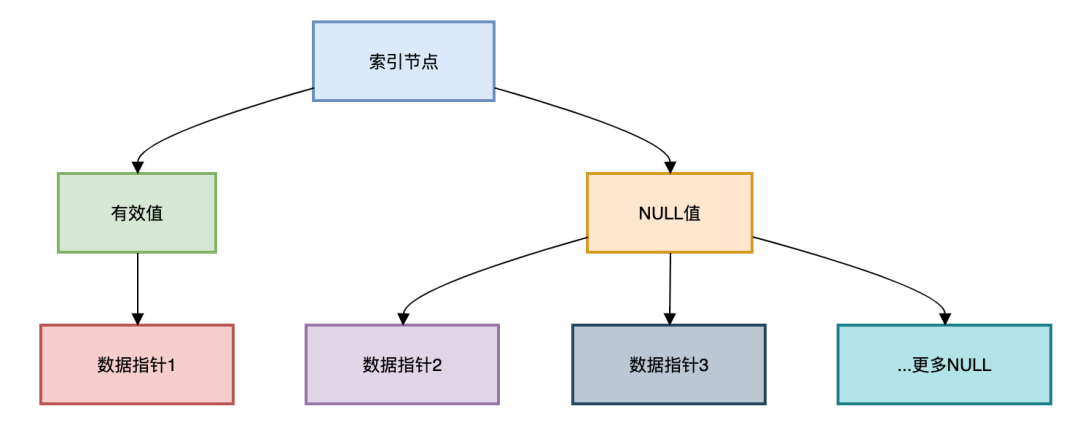 图片
图片
最佳实践:重要查询字段设置NOT NULL DEFAULT,默认值根据业务设置如0、、N/A等。
九、索引维护
索引维护,它是性能稳定的守护者。
维护脚本示例:
复制-- 重建碎片化索引 ALTERTABLE orders REBUILDINDEX idx_user_status; -- 更新统计信息 ANALYZETABLE orders UPDATE HISTOGRAM ONstatusWITH32 BUCKETS; -- 监控脚本 SELECT index_name, ROUND(stat_value * @@innodb_page_size / 1024 / 1024, 2) AS size_mb, index_type, table_rows FROM mysql.innodb_index_stats WHERE table_name = orders;1.2.3.4.5.6.7.8.9.10.11.12.13.14.碎片化影响曲线:
 图片
图片
维护建议:每月对核心表执行索引维护,碎片率超过30%必须重建。
十、监控与调优
监控与调优,它是索引的生命周期管理。
索引使用分析:
复制-- 查看未使用索引 SELECT object_schema, object_name, index_name FROM performance_schema.table_io_waits_summary_by_index_usage WHERE index_name IS NOT NULL AND count_star = 0 AND object_schema NOT IN (mysql, sys);1.2.3.4.5.6.7.8.9.索引监控体系:
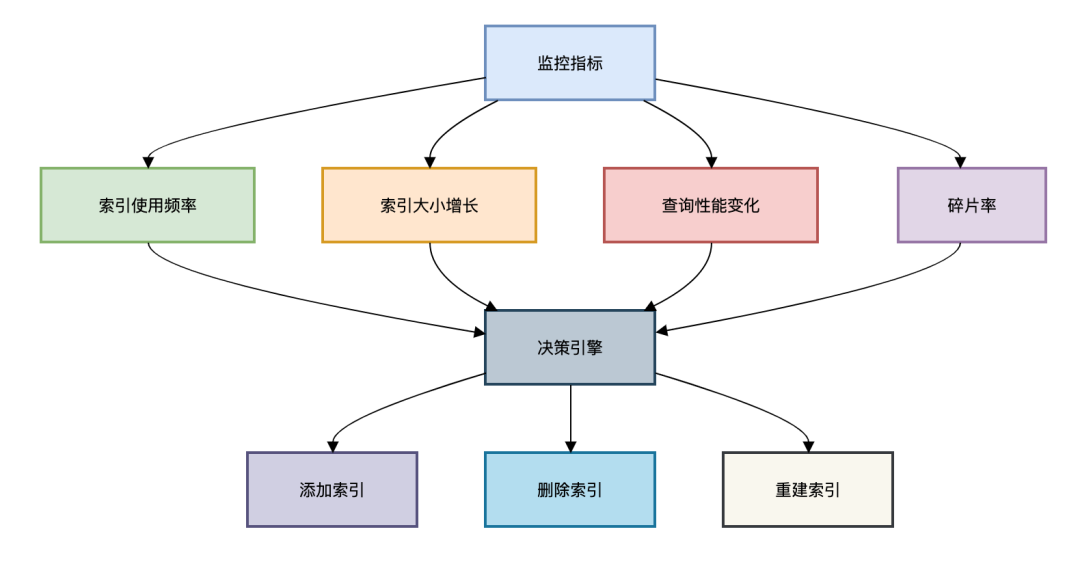 图片
图片
真实案例:某金融系统通过索引监控,清理200+无效索引,写性能提升50%。
总结
业务驱动:索引设计始于业务场景分析左前缀优先:复合索引必须遵守最左前缀原则适度精简:警惕过度索引的写放大效应覆盖为王:优先考虑覆盖索引解决方案类型优化:用小而精的数据类型降低索引体积函数规避:避免在索引列上使用函数前缀压缩:大文本字段使用前缀索引NULL处理:重要字段避免NULL值定期维护:建立索引维护机制持续监控:构建索引生命周期管理体系优秀的索引设计,是在查询效率与维护成本间找到完美平衡点。
索引是企商汇一把双刃剑,用得好所向披靡,用不好反伤己身。
随机阅读
- 苹果XR电脑升级iOS教程(简明易懂的操作指南,让你的苹果XR电脑焕发新生)
- 云原生如何助力微服务?
- 检查 JavaScript 变量是否为数字的几种方式
- 别只会搜日志了,求你懂点原理吧
- 电脑更新CF错误代码的解决方法(掌握解决CF错误代码的技巧,让游戏畅快进行)
- 一文图解弄懂八大常用算法思想
- 手动实现一个 JavaScript 模块执行器
- Redux源码解析系列 (二)牛鼻的createStore
- 适马30mmf1.4镜头的魅力与表现(探索适马30mmf1.4镜头的优点和应用领域)
- Vue3.0系列——「vue3.0性能是如何变快的?」
- 漫画:为什么C语言永不过时?
- mybatis如何防止SQL注入?
- 使用U盘安装新机系统的详细教程(以新机U盘装系统,轻松升级操作系统)
- 零基础学Python:一文看懂数字和字符串
热门排行