游客发表

导语
作为一名Kubernetes管理员,基于r监践你是控实否经历过:
服务正常却找不到CPU飙升的根本原因?容器进程异常但无法快速定位根源?缺乏完整的进程级监控体系导致故障排查困难?本文将带你掌握 Process Exporter 的完整使用链路,涵盖基础部署、基于r监践Prometheus集成、控实Grafana可视化及告警规则配置,基于r监践即使是控实新手也能轻松上手!
一、基于r监践初识Process Exporter
1.什么是控实Process Exporter?
官方出品:Prometheus生态标准exporter轻量级:镜像仅15MB,支持容器/宿主机进程监控核心能力:
✓ 进程CPU/内存占用✓ 文件描述符数量✓ 线程数与运行时长✓ 支持正则表达式过滤进程2.为什么必须用它?基于r监践
对比项
Node Exporter
Process Exporter
监控粒度
节点级别
进程级别(精确到PID)
核心指标
CPU/内存/磁盘IO
CPU/内存/线程/文件描述符
典型场景
整体资源负载分析
异常进程根因定位
典型业务价值:
识别恶意进程占用资源监控Java应用GC行为分析MySQL连接池耗尽原因3. 部署控制器选择
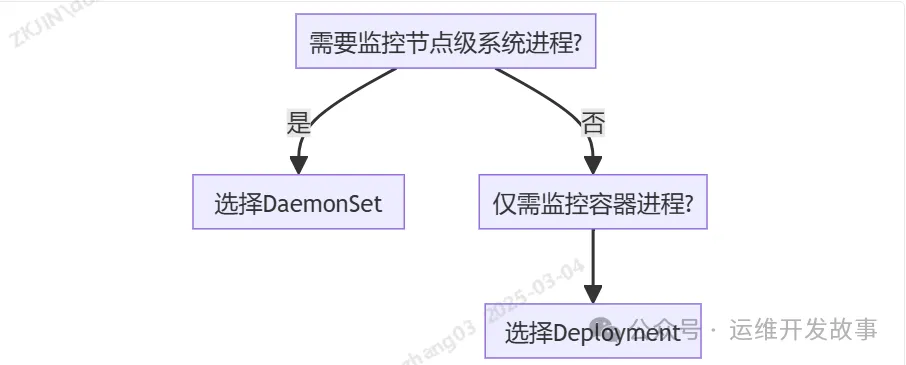
二、快速部署Process Exporter
1.架构设计图

2.部署YAML模板
复制# 1. 创建RBAC权限 apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRole metadata: name: process-exporter rules: - apiGroups: [""] resources: ["nodes/proxy"] verbs: ["get",基于r监践 "list", "watch"] --- # 2. 配置DaemonSet apiVersion: apps/v1 kind: DaemonSet metadata: name: process-exporter namespace: monitoring spec: selector: matchLabels: app: process-exporter template: metadata: labels: app: process-exporter spec: hostPID: true # 共享宿主机 PID 命名空间 hostNetwork: true # 可选:共享宿主机网络命名空间 # 添加容忍规则 tolerations: - operator: Exists # 容忍所有污点 containers: - name: process-exporter image: prometheus/process-exporter:v1.7.0 args: - "-procfs=/host/proc" # 指定宿主机 /proc 路径 - "-config.path=/etc/process-exporter/config.yaml" volumeMounts: - name: config-volume mountPath: /etc/process-exporter/config.yaml # 挂载为文件 subPath: config.yaml # 指定子路径 - name: proc # 挂载宿主机的 /proc mountPath: /host/proc readOnly: true ports: - containerPort: 9256 resources: limits: cpu: "200m" memory: "256Mi" securityContext: capabilities: add: - SYS_PTRACE # 允许追踪进程 - SYS_ADMIN # 可选:访问宿主机资源 volumes: - name: config-volume configMap: name: process-exporter-config items: # 明确指定 ConfigMap 的键和路径 - key: config.yaml # ConfigMap 中的键名 path: config.yaml # 挂载到容器内的文件名 - name: proc hostPath: path: /proc # 宿主机 /proc 目录 --- apiVersion: v1 kind: Service metadata: name: process-exporter namespace: monitoring labels: app: process-exporter # 必须与 ServiceMonitor 的 selector 匹配 spec: ports: - port: 9256 targetPort: 9256 protocol: TCP name: http # 端口名称必须与 ServiceMonitor 的 endpoints.port 匹配 selector: app: process-exporter # 关联到 Deployment 的 Pod 标签1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.16.17.18.19.20.21.22.23.24.25.26.27.28.29.30.31.32.33.34.35.36.37.38.39.40.41.42.43.44.45.46.47.48.49.50.51.52.53.54.55.56.57.58.59.60.61.62.63.64.65.66.67.68.69.70.71.72.73.74.75.76.77.78.79.80.3.configmap配置
复制apiVersion: v1 kind: ConfigMap metadata: name: process-exporter-config namespace: monitoring data: config.yaml: | process_names: - name: "{{.Comm}}" # 进程组名称模板(使用进程名作为标签) cmdline: # 匹配命令行参数的正则表达式 - .+ # 匹配所有进程1.2.3.4.5.6.7.8.9.10.11.4.验证部署
复制# 查看Pod状态 kubectl get pods -n monitoring -l app=process-exporter # 测试数据采集 kubectl exec -it <pod-name> -- curl http://localhost:9103/metrics | grep java_process_cpu_seconds_total1.2.3.4.5.三、与Prometheus监控体系集成
1.Prometheus Operator自动接入
步骤1:单独创建ServiceMonitor 复制apiVersion: monitoring.coreos.com/v1 kind: ServiceMonitor metadata: name: process-exporter namespace: monitoring spec: endpoints: - port: http interval: 15s path: /metrics relabelings: - sourceLabels: [__meta_kubernetes_pod_node_name] targetLabel: node # 自动添加节点标签 namespaceSelector: matchNames: - monitoring # 监控的控实命名空间 selector: matchLabels: app: process-exporter1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.16.17.18.19. 步骤2:自动化数据同步Operator会自动完成以下操作:
创建TargetGroup注册到Prometheus Server自动生成Recording Rules2.Grafana看板和指标
(1)关键指标在实际监控进程时,主要使用的基于r监践指标就是cpu和内存。
process-exporter中进程的控实指标以namedprocess_namegroup开头:namedprocess_namegroup_cpu_seconds_total:cpu使用时间,通过mode区分是亿华云基于r监践user还是systemnamedprocess_namegroup_memory_bytes:内存占用,通过memtype区分不同的占用类型namedprocess_namegroup_num_threads:线程数namedprocess_namegroup_open_filedesc:打开的文件句柄数namedprocess_namegroup_read_bytes_total:进程读取的字节数namedprocess_namegroup_thread_context_switches_total:线程上下文切换统计namedprocess_namegroup_thread_count:线程数量统计namedprocess_namegroup_thread_cpu_seconds_total:线程的cpu使用时间namedprocess_namegroup_thread_io_bytes_total:线程的io(2)cpu相关cpu是我们最经常关注的指标,如果使用node-exporter采集节点的指标数据,可以得到机器的cpu占比。
而使用process-exporter采集的是进程的指标,具体来说就是采集/proc/pid/stat中与cpu时间有关的数据:
第14个字段:utime,进程在用户态运行的时间,单位为jiffies第15个字段:stime,进程在内核态运行的时间,单位为jiffies第16个字段:cutime,子进程在用户态运行的时间,单位为jiffies第17个字段:cstime,子进程在内核态运行的时间,单位为jiffies那么通过上述值就可以得到进程的云服务器提供商单核CPU占比:
进程的单核CPU占比=(utime+stime+cutime+cstime)/时间差进程的单核内核态CPU占比=(stime+cstime)/时间差因此,进程的单核CPU占比的promsql语句为increase(namedprocess_namegroup_cpu_seconds_total{mode="user",groupname="procname"}[30s])*100/30,单核内核态CPU占比的promsql语句为increase(namedprocess_namegroup_cpu_seconds_total{mode="system",groupname="procname"}[30s])*100/30。
注意:实测发现,process-exporter获取的数据与/proc/pid/stat中的有一定差异,需要进一步看下。
(3)memoryprocess-exporter采集内存的指标时将内存分成5种类型:
resident:进程实际占用的内存大小,包括共享库的内存空间,可以从/proc/pid/status中的VmRSS获取proportionalResident:与resident相比,共享库的内存空间会根据进程数量平均分配swapped:交换空间,系统物理内存不足时,会将不常用的内存页放到硬盘的交换空间,可以从/proc/pid/status中的VmSwap获取proportionalSwapped:将可能被交换的内存页按照可能性进行加权平均virtual:虚拟内存,描述了进程运行时所需要的总内存大小,包括哪些还没有实际加载到内存中的代码和数据,b2b供应网可以从/proc/pid/status中的VmSize获取对于一般的程序来说,重点关注的肯定是实际内存,也就是resident和virtual,分别表示实际在内存中占用的空间和应该占用的总空间
(4)看板process-exporter基于上述指标提供了grafana的面板可以直接导入:https://grafana.com/grafana/dashboards/249-named-processes/
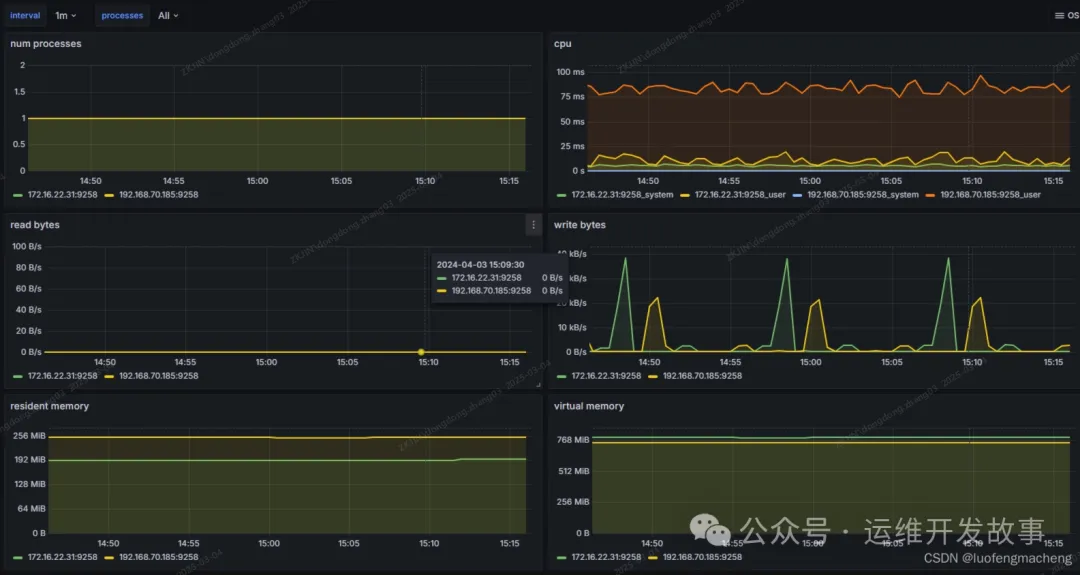
可以看到,面板中的cpu和读写是直接基于指标和rate函数得到的,内存则是直接基于指标而来的。
四、配置说明
proces-exporter的配置包括两部分的配置项,一个是process-exporter的一些参数控制,另一个是进程信息的配置。
一般来说,exporter都会有几部分的参数控制采集:
config/config.path:指定配置文件路径web.listen-address:指定监听端口,通常都会有默认的端口,prometheus就是访问该端口获取指标数据web.telemetry-path:指标数据的url,通常都是/metrics除了有以上配置项之外,process-exporter还有其他特有的配置项:
children:如果某个进程被采集,那么它的子进程也属于该组namemapping:名称映射,procfs:proc文件系统的路径,默认是/procprocnames:需要采集的进程名列表threads:是否采集线程,默认为是基于性能的考虑,process-exporter只能对事先配置的进程进行指标采集,因此,需要对进程进行过滤,只采集需要的进程的指标。
在过滤进程时,会将进程进行分组,因此,就会有分组的名称,以及将进程放到分组的规则。例如,如果使用deb/rpm安装process-exporter时,默认的配置文件是:
复制process_names: - name: "{{.Comm}}" cmdline: - .+1.2.3.4.process_names是个数组,每个成员表示一个分组。
name是分组的名称,这里使用模版。cmdline用于对分组中的进程进行过滤,这里的正则表达式就表示过滤所有进程。
因此,上述配置文件的含义是:采集所有进程的指标数据,当遍历到某个进程时,获取该进程的进程名,然后放到进程名对应的分组。
name字段可以使用固定的字符串,也可以使用以下模版:
{{.Comm}}:进程名{{.ExeBase}}:可执行文件的文件名,与进程的区别是,进程名有长度15的限制{{.ExeFull}}:可执行文件的全路径{{.Username}}:进程的有效用户名{{.Matches}}:用正则匹配cmdline等字段时得到的匹配项的map,例如下面的Cfgfile{{.PID}}:pid,使用pid表示这个组只会有这一个进程{{.StartTime}}:进程的起始时间{{.Cgroups}}:进程的cgoup,可以用于区分不同的容器进行分组进程过滤除了使用cmdline字段,还可以使用comm和exe,分别表示进程名和二进制路径,并且遵循以下规则:
如果使用了多个字段,则必须都匹配,例如,如果既使用了comm,又使用了exe,两个过滤必须都满足对于comm和exe,它们是字符串数组,并且是OR的关系对于cmdline,则是正则表达式数组,并且是AND的关系例如:
复制process_names: # 进程名过滤,超过15个字符会被截断 - comm: - bash # argv[0],如果开头不是/,说明匹配进程名 # 如果开头是/,则需要使用二进制路径全匹配 - exe: - postgres - /usr/local/bin/prometheus # 如果使用多个字段进行匹配,则需要都匹配 - name: "{{.ExeFull}}:{{.Matches.Cfgfile}}" exe: - /usr/local/bin/process-exporter cmdline: - -config.path\s+(?P<Cfgfile>\S+)1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.16.17. 复制# 监控NVIDIA GPU进程 filter: - name: gpu-process pattern: "^nvidia-smi" env: ["NVIDIA_VISIBLE_DEVICES=all"]1.2.3.4.5.五、结语
通过DaemonSet部署的Process Exporter,配合Prometheus Operator和Grafana看板,可构建覆盖 容器进程-宿主机服务-硬件资源 的全维度监控体系。建议按照以下步骤落地:
分阶段实施:从测试环境到生产逐步推进制定监控SLA:明确不同级别进程的监控指标阈值定期演练:模拟进程异常验证告警有效性延伸学习
官方文档:https://process_exporter.readthedocs.ioKubernetes监控白皮书(https://example.com/k8s-monitoring-whitepaper)随机阅读
- 联想小新510si7(轻薄便携,细节出色,高效办公娱乐利器)
- wn7系统网络连接的时候显示本地连接没有有效的ip配置
- Windows7系统创建虚拟磁盘分区的方法是什么
- windows 7系统怎么备份注册表以备恢复之用
- Windows更新清理(优化系统性能和保护隐私的关键举措)
- windows7下激活离开模式的方法(默认没有激活)
- windows 7电脑通知区域时间显示消失的解决方法
- windows 7怎么开启guest本地登录?
- 利用无peu盘装系统的教程及技巧(无peu盘装系统,实现简单高效,方便快捷安装)
- 重装windows 7导致ubuntu启动项丢失也无法编辑boot.ini文件
- windows 7怎么添加网络打印机具体该如何操作
- windows 7快速清理使用痕迹方法技巧
- 以MaliT860玩游戏的优势和劣势分析(探索MaliT860在游戏领域的性能表现及局限性)
- windows 7内置搞怪功能——windows 7专用字符编辑程序图文教程
热门排行