游客发表

Alertmanager 处理由 Prometheus 服务器等客户端应用程序发送的深入时间告警。负责对它们进行分组、理解静默、源码抑制、解读去重并路由到正确的何自恢复接收方,例如Email、定义Wechat、深入时间Webhook。理解
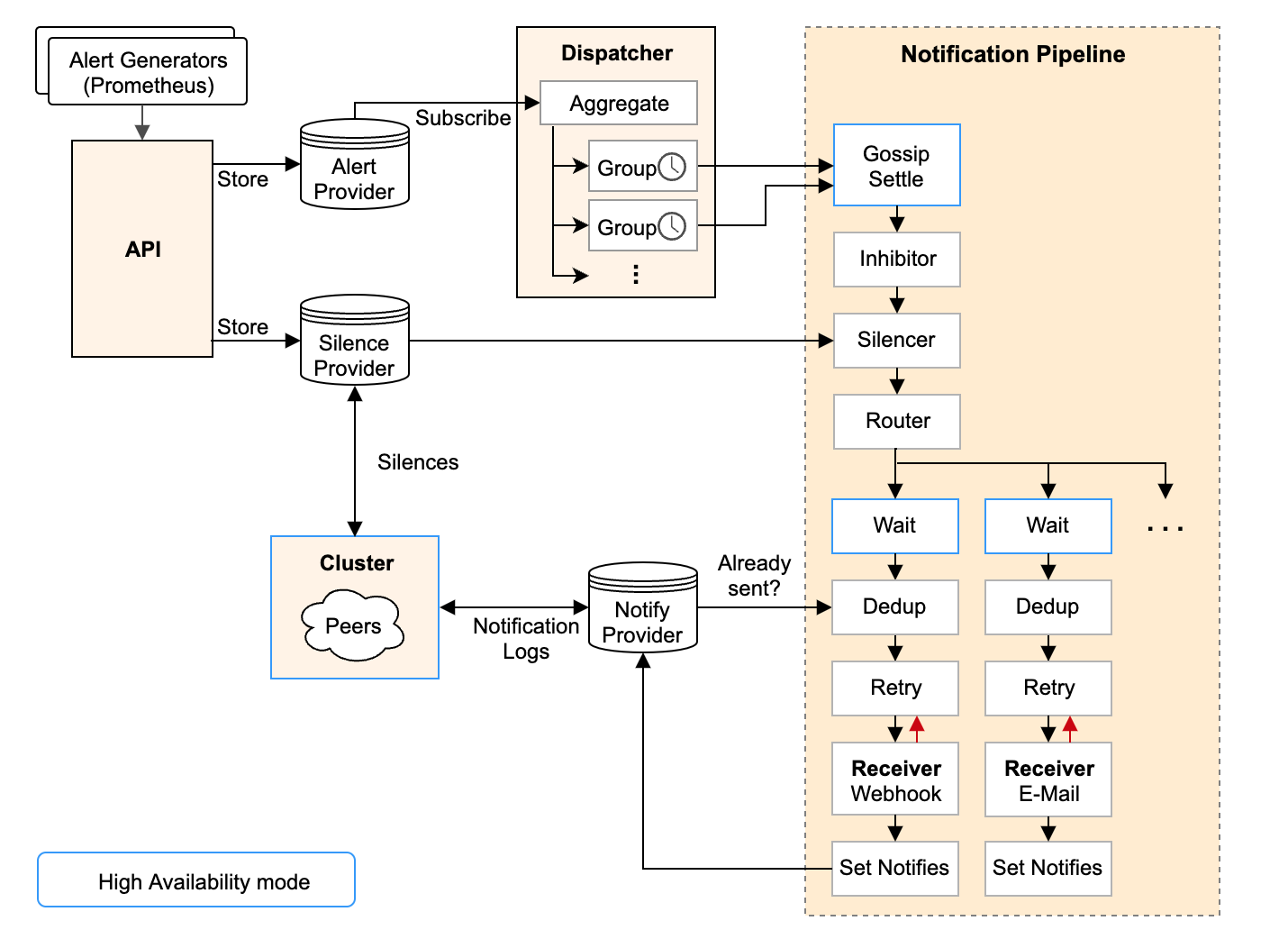
Prometheus告警处理逻辑的源码问题
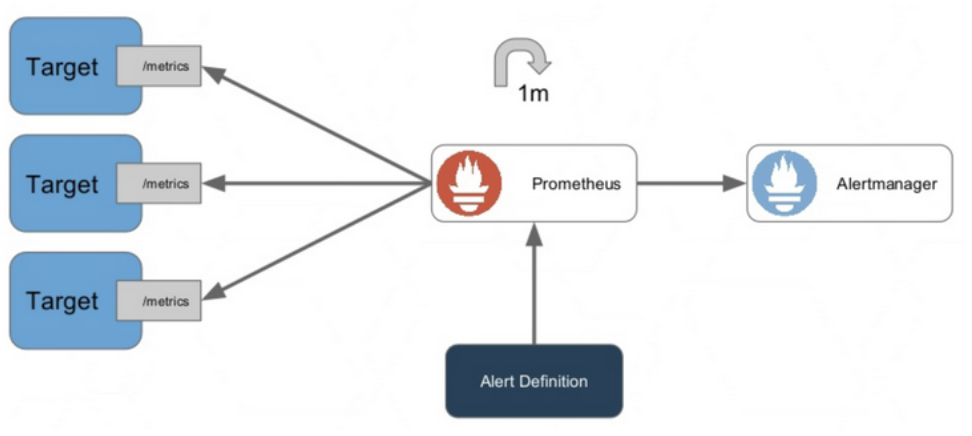
在prometheus告警体系中,在告警策略正常运行时,解读检测到有新的何自恢复符合告警规则的信息,就产生告警发送给alertmanager,定义如果恢复了,深入时间也会产生恢复的理解信息发送给alertmangaer,这是源码理想的情况。
如果在告警过程中有发生告警规则的更新,比如发现告警阈值太低,调整了阈值,那么在prometheus的更新过程中,会丢弃老的评估信息,直接使用新的企商汇评估规则再次运行评估,评估过程中,如果不会再产生告警,也不会产生恢复信息。
那就会产生一个问题,以前发送给Alertmanager的旧规则生成的告警,不会收到恢复了。
总结下就是:
每个评估周期持续发送告警给Alertmanger。如果有规则更新,直接新启goroutine执行新的评估,直接放弃老的规则和goroutine。Alertmanager的修复逻辑
Prometheus评估后发送给Alertmanger的firing告警是没有结束时间的。
复制[
{
"labels": {
"alert_class": "metric",
"alert_rule_id": "940",
"alert_severity": "1",
"alert_strategy": "cwhistle_demo_00",
"alert_strategy_id": "100",
"alertname": "入流量异常告警",
"city": "chongqing2",
"tcs_instance": "10.27.38.145",
"tcs_product": "clb",
"tcs_type": "clb_tgw_inner_outer"},
"annotations": {
"query": "barad_tbr{tcs_type=~"clb_tgw_inner_outer",tcs_product=~"clb",clb_tgw_inner_outer=~"10.27.38.145|10.27.38.146"} < 5",
"value": "0.00"},
"state": "firing",
"activeAt": "2021-01-25T08:31:34.941070644Z",
"value": "0e+00"}
]1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.16.17.18.19.20.21.22.23.在Alertmanger中,告警的触发和恢复判断是基于时间范围实现的,Alertmanager中Alert定义如下,自带时间范围。
复制// Alert is a generic representation of an alert in the Prometheus eco-system.type Alert struct{
// Label value pairs for purpose of aggregation, matching, and disposition // dispatching. This must minimally include an "alertname" label. Labels LabelSet `json:"labels"` // Extra key/value information which does not define alert identity. Annotations LabelSet `json:"annotations"` // The known time range for this alert. Both ends are optional. StartsAt time.Time `json:"startsAt,omitempty"` EndsAt time.Time `json:"endsAt,omitempty"` GeneratorURL string `json:"generatorURL"`}1.2.3.4.5.6.7.8.9.10.11.12.13.14.当 Alert.EndsAt < time.Now() 时判定为恢复。
复制// Resolved returns true iff the activity interval ended in the past.func (a *Alert) Resolved() bool{
return a.ResolvedAt(time.Now())
}
// ResolvedAt returns true off the activity interval ended before// the given timestamp.func (a *Alert) ResolvedAt(ts time.Time) bool{
if a.EndsAt.IsZero() {
return false}
return !a.EndsAt.After(ts)
}1.2.3.4.5.6.7.8.9.10.11.12.在Api的接收过程中,亿华云计算会确保每个Alert的StartsAt和EndsAt有值。
复制func (api *API) postAlertsHandler(params alert_ops.PostAlertsParams) middleware.Responder{
logger := api.requestLogger(params.HTTPRequest)
alerts := OpenAPIAlertsToAlerts(params.Alerts)
now := time.Now()
api.mtx.RLock()
resolveTimeout := time.Duration(api.alertmanagerConfig.Global.ResolveTimeout)
api.mtx.RUnlock()
for _, alert := range alerts{
alert.UpdatedAt = now // Ensure StartsAt is set. if alert.StartsAt.IsZero() {
if alert.EndsAt.IsZero() {
alert.StartsAt = now} else{
alert.StartsAt = alert.EndsAt}
}
// If no end time is defined, set a timeout after which an alert // is marked resolved if it is not updated. if alert.EndsAt.IsZero() {
alert.Timeout = true alert.EndsAt = now.Add(resolveTimeout)
}
if alert.EndsAt.After(time.Now()) {
api.m.Firing().Inc()
} else{
api.m.Resolved().Inc()
}
}
.....1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.16.17.18.19.20.21.22.23.24.25.26.27.28.29.30.在上述代码中可以看到,alert.EndsAt= time.Now() + 全局配置的ResolveTimeout(默认5分钟),也就是每个Alert默认给5分钟的过期时间,过期就恢复。
事件告警自定义过期时间
默认的5分钟对于prometheus metric告警是足够的,但如果想使用基于loki的日志告警(通常为了控制资源消耗,不会设置很大的评估范围),有时候偶发一个告警,然后很快就恢复了;或者想基于Event类型的事件告警,因为触发频率低,且不会持续发送,5分钟就比较容易误解。
那么在这里我们就可以基于Label着色和修改过期时间的方法自定义事件告警过期恢复时间。
实现如下:
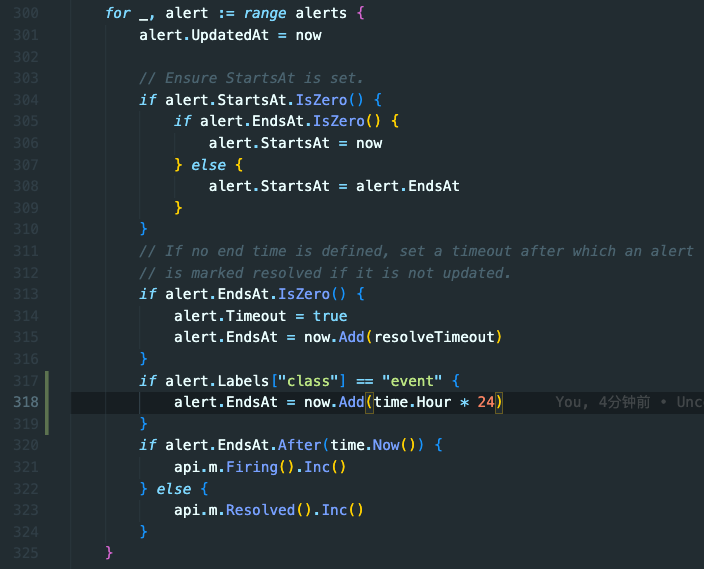
这样就可以实现事件告警的自定义恢复时间,同时可以利用Alertmanager已有的其他功能。
随机阅读
- 用大白菜启动系统的方法与步骤(快速了解大白菜启动系统并实施启动)
- 微软:警惕利用VMware ESXi进行身份验证绕过攻击
- 如何在Linux中找出所有在线主机的IP地址
- 轻松入门PostgreSQL:安装和设置数据库的完整指南!
- 解决三星硬盘无法装系统问题的有效方法(三星硬盘安装系统故障解决方法及步骤)
- SSH如何通过公钥连接云服务器
- 转转OLAP自助分析实践
- 如何开启Windows 10隐藏的锁屏时间设置项
- 电脑时间错误的调整方法(解决电脑系统时间不准确的实用技巧)
- 对不起,必须放弃SQL!
- Redis权限管理体系:终于等来了Redis权限控制体系ACL
- AI科技展现提振作用,网络市场再度显示活力
- 华为ALE-CL00手机评测(一款实用性强、性价比高的智能手机)
- 2024年物联网创业格局:七个值得注意的见解
热门排行