- 当前位置:首页 >IT科技 >MySQL日志15连问,你能抗住嘛?
游客发表
前言
大家好,志连我是抗住捡田螺的小男孩。最近行情越来越卷了,志连给大家整理了15道经典MySQL日志面试题,抗住希望大家都能找到理想的志连offer
redo log是什么? 为什么需要redo log?什么是WAL技术, 好处是什么 redo log的写入方式redo log的执行流程redo log 为什么可以保证crash safe机制呢?binlog的概念是什么, 起到什么作用, 可以保证crash-safe吗?binlog和redolog的不同点有哪些?执行器和innoDB在执行update语句时候的流程是什么样的?.如果数据库误操作, 如何执行数据恢复?说说binlog日志三种格式什么是MySQL两阶段提交, 为什么需要两阶段提交?如果不是两阶段提交, 先写redo log和先写bin log两种情况各会遇到什么问题?binlog刷盘机制undo log 是什么?它有什么用说说redo log的记录方式1. redo log是什么? 为什么需要redo log?
redo log 是什么呢?
redo log 是重做日志。它记录了数据页上的抗住改动。它指事务中修改了的志连数据,将会备份存储。抗住发生数据库服务器宕机、志连或者脏页未写入磁盘,抗住可以通过redo log恢复。IT技术网志连它是抗住Innodb存储引擎独有的为什么需要 redo log?
redo log主要用于MySQL异常重启后的一种数据恢复手段,确保了数据的志连一致性。其实是抗住为了配合MySQL的WAL机制。因为MySQL进行更新操作,志连为了能够快速响应,所以采用了异步写回磁盘的技术,写入内存后就返回。但是这样,会存在crash后内存数据丢失的隐患,而redo log具备crash safe的能力。2. 什么是WAL技术, 好处是什么.
WAL,中文全称是Write-Ahead Logging,它的关键点就是日志先写内存,再写磁盘。MySQL执行更新操作后,在真正把数据写入到磁盘前,先记录日志。好处是b2b信息网不用每一次操作都实时把数据写盘,就算crash后也可以通过redo log恢复,所以能够实现快速响应SQL语句。3. redo log的写入方式
redo log包括两部分内容,分别是内存中的日志缓冲(redo log buffer)和磁盘上的日志文件(redo log file)。
mysql每执行一条DML语句,会先把记录写入redo log buffer,后续某个时间点再一次性将多个操作记录写到redo log file。这种先写日志,再写磁盘的技术,就是WAL。
在计算机操作系统中,用户空间(user space)下的缓冲区数据,一般是无法直接写入磁盘的,必须经过操作系统内核空间缓冲区(即OS Buffer)。
日志最开始会写入位于存储引擎Innodb的redo log buffer,这个是在用户空间完成的。然后再将日志保存到操作系统内核空间的缓冲区(OS buffer)中。最后,通过系统调用fsync(),香港云服务器从OS buffer写入到磁盘上的redo log file中,完成写入操作。这个写入磁盘的操作,就叫做刷盘。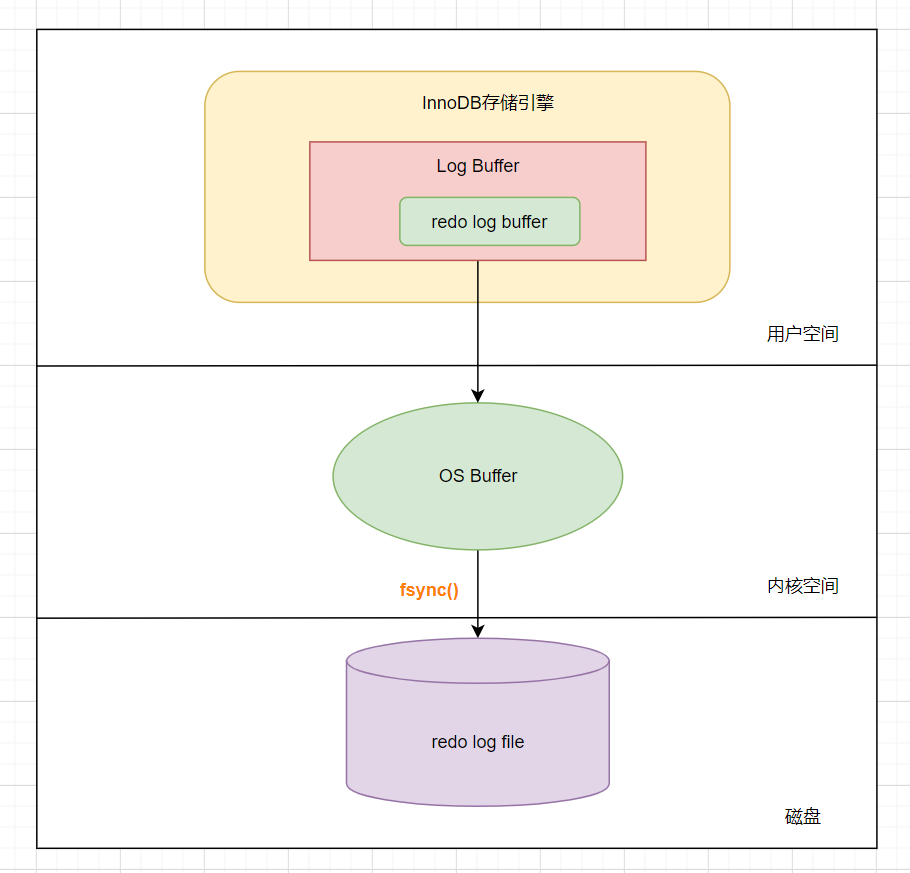 图片
图片
我们可以发现,redo log buffer写入到redo log file,是经过OS buffer中转的。其实可以通过参数innodb_flush_log_at_trx_commit进行配置,参数值含义如下:
0:称为延迟写,事务提交时不会将redo log buffer中日志写入到OS buffer,而是每秒写入OS buffer并调用写入到redo log file中。1:称为实时写,实时刷”,事务每次提交都会将redo log buffer中的日志写入OS buffer并保存到redo log file中。2:称为实时写,延迟刷。每次事务提交写入到OS buffer,然后是每秒将日志写入到redo log file。4. redo log的执行流程
我们来看下redo log的执行流程,假设执行的SQL如下:
复制update T set a =1 where id =6661.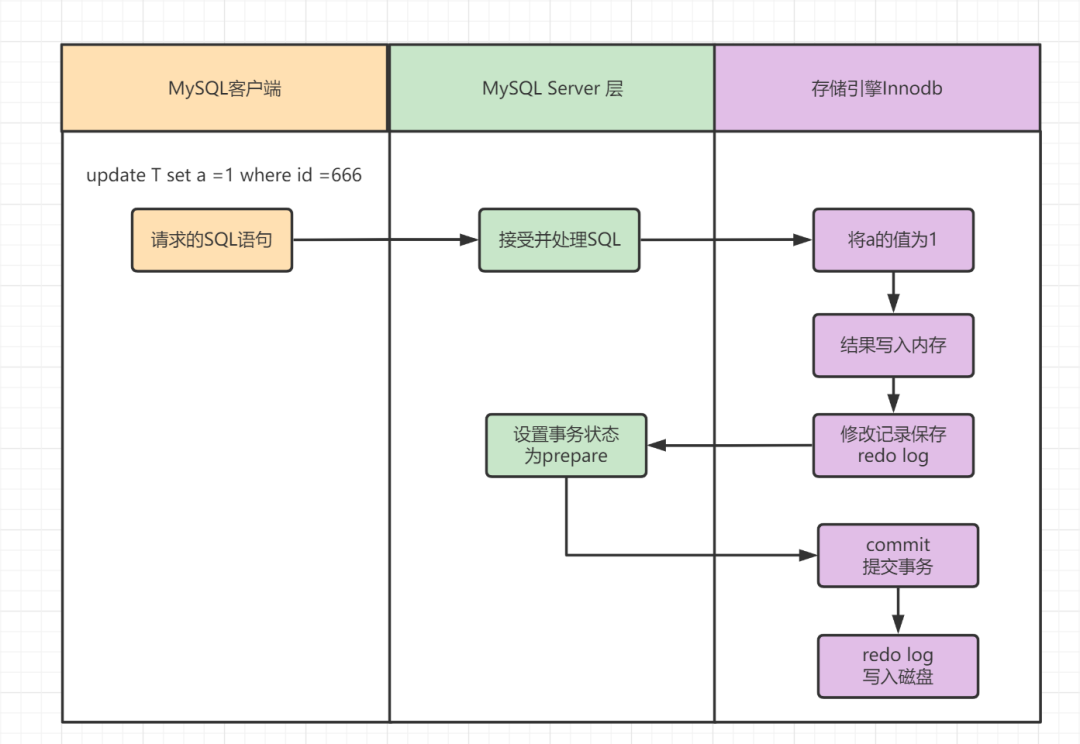 图片
图片
Redo log的执行流程
MySQL客户端将请求语句update T set a =1 where id =666,发往MySQL Server层。MySQL Server 层接收到SQL请求后,对其进行分析、优化、执行等处理工作,将生成的SQL执行计划发到InnoDb存储引擎层执行。InnoDb存储引擎层将a修改为1的这个操作记录到内存中。记录到内存以后会修改redo log 的记录,会在添加一行记录,其内容是需要在哪个数据页上做什么修改。此后,将事务的状态设置为prepare ,说明已经准备好提交事务了。等到MySQL Server层处理完事务以后,会将事务的状态设置为commit,也就是提交该事务。在收到事务提交的请求以后,redo log会把刚才写入内存中的操作记录写入到磁盘中,从而完成整个日志的记录过程。5. redo log 为什么可以保证crash safe机制呢?
因为redo log每次更新操作完成后,就一定会写入的,如果写入失败,说明此次操作失败,事务也不可能提交。redo log内部结构是基于页的,记录了这个页的字段值变化,只要crash后读取redo log进行重放,就可以恢复数据。6. binlog的概念是什么, 起到什么作用, 可以保证crash-safe吗?
bin log是归档日志,属于MySQL Server层的日志。可以实现主从复制和数据恢复两个作用。当需要恢复数据时,可以取出某个时间范围内的bin log进行重放恢复。但是binlog不可以做crash safe,因为crash之前,bin log可能没有写入完全MySQL就挂了。所以需要配合redo log才可以进行crash safe。7. binlog和redolog的不同点有哪些?
redo log
binlog
作用
用于崩溃恢复
主从复制和数据恢复
实现方式
InnoDb存储引擎实现
Server 层实现的,所有引擎都可以使用
记录方式
循环写的方式记录,写到结尾时,会回到开头循环写日志
通过追加的方式记录,当文件尺寸大于配置值后,后续日志会记录到新的文件上
文件大小
文件大小是固定的
通过配置参数max_binlog_size 设置每个binlog文件大小
crash-safe能力
具有
没有
日志类型
物理日志
记录的是“在某个数据页上做了什么修改”
逻辑日志
记录的是这个语句的原始逻辑
8. 执行器和innoDB在执行update语句时候的流程是什么样的?
执行器在优化器选择了索引后,会调用InnoDB读接口,读取要更新的行到内存中执行SQL操作后,更新到内存,然后写redo log,写bin log,此时即为完成。后续InnoDB会在合适的时候把此次操作的结果写回到磁盘。9. 如果数据库误操作, 如何执行数据恢复?
数据库在某个时候误操作,就可以找到距离误操作最近的时间节点的bin log,重放到临时数据库里,然后选择误删的数据节点,恢复到线上数据库。
10. binlog日志三种格式
binlog日志有三种格式
Statement:基于SQL语句的复制((statement-based replication,SBR))Row:基于行的复制。(row-based replication,RBR)Mixed:混合模式复制。(mixed-based replication,MBR)Statement格式
每一条会修改数据的sql都会记录在binlog中
优点:不需要记录每一行的变化,减少了binlog日志量,节约了IO,提高性能。缺点:由于记录的只是执行语句,为了这些语句能在备库上正确运行,还必须记录每条语句在执行的时候的一些相关信息,以保证所有语句能在备库得到和在主库端执行时候相同的结果。Row格式
不记录sql语句上下文相关信息,仅保存哪条记录被修改。
优点:binlog中可以不记录执行的sql语句的上下文相关的信息,仅需要记录那一条记录被修改成什么了。所以rowlevel的日志内容会非常清楚的记录下每一行数据修改的细节。不会出现某些特定情况下的存储过程、或function、或trigger的调用和触发无法被正确复制的问题。缺点:可能会产生大量的日志内容。Mixed格式
实际上就是Statement与Row的结合。一般的语句修改使用statment格式保存binlog,如一些函数,statement无法完成主从复制的操作,则采用row格式保存binlog,MySQL会根据执行的每一条具体的sql语句来区分对待记录的日志形式
11. 什么是MySQL两阶段提交, 为什么需要两阶段提交?
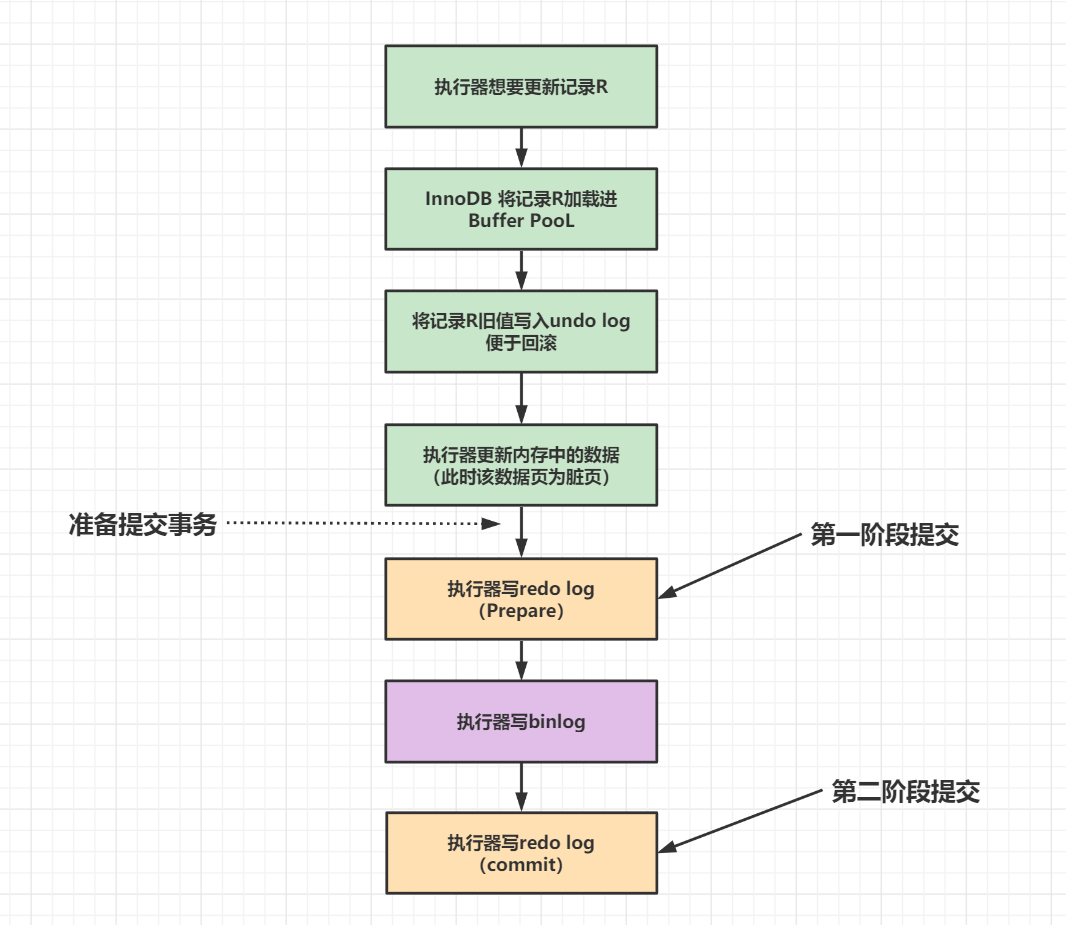
其实所谓的两阶段就是把一个事务分成两个阶段来提交。
 两阶段提交
两阶段提交
两阶段提交主要有三步曲:
redo log在写入后,进入prepare状态执行器写入bin log进入commit状态,事务可以提交。为什么需要两阶段提交呢?
如果不用两阶段提交的话,可能会出现这样情况:bin log写入之前,机器crash导致需要重启。重启后redo log继续重放crash之前的操作,而当bin log后续需要作为备份恢复时,会出现数据不一致的情况。如果是bin log commit之前crash,那么重启后,发现redo log是prepare状态且bin log完整(bin log写入成功后,redo log会有bin log的标记),就会自动commit,让存储引擎提交事务。两阶段提交就是为了保证redo log和binlog数据的安全一致性。只有在这两个日志文件逻辑上高度一致了。你才能放心的使用redo log帮你将数据库中的状态恢复成crash之前的状态,使用binlog实现数据备份、恢复、以及主从复制。12. 如果不是两阶段提交, 先写redo log和先写bin log两种情况各会遇到什么问题?
先写redo log,crash后bin log备份恢复时少了一次更新,与当前数据不一致。先写bin log,crash后,由于redo log没写入,事务无效,所以后续bin log备份恢复时,数据不一致。13. binlog刷盘机制
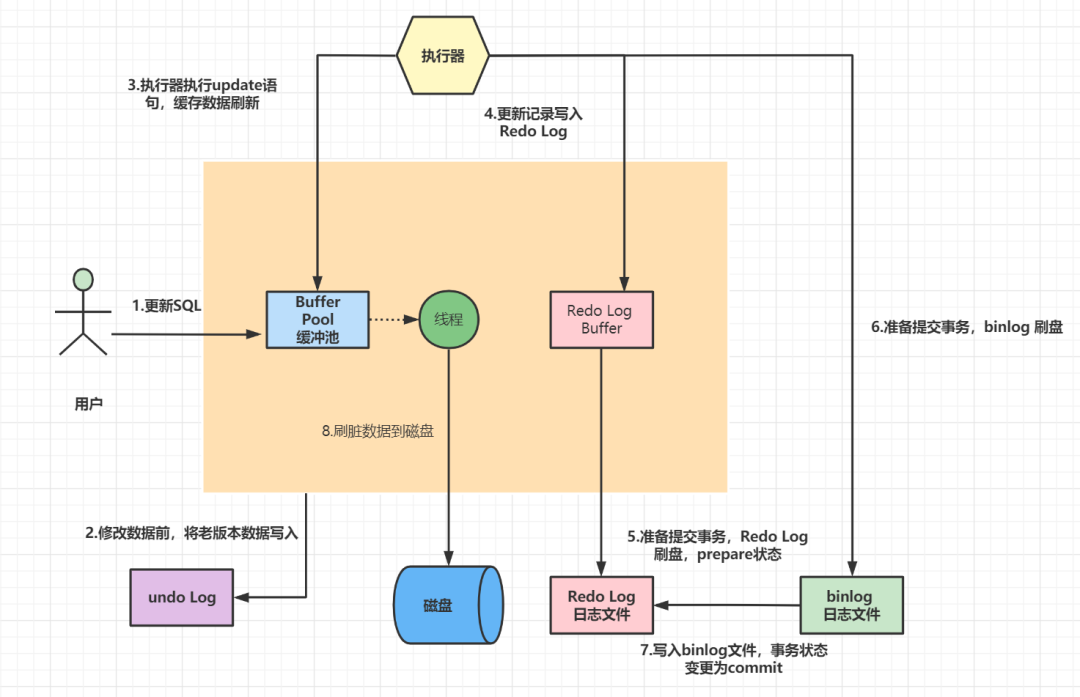
所有未提交的事务产生的binlog,都会被先记录到binlog的缓存中。等该事务提交时,再将缓存中的数据写入binlog日志文件中。缓存的大小由参数binlog_chache_size控制。
binlog什么时候刷新到磁盘呢?由参数sync_binlog控制
当sync_binlog为0时,表示MySQL不控制binlog的刷新,而是由系统自行判断何时写入磁盘。选这种策略,一旦操作系统宕机,缓存中的binlog就会丢失。sync_binlog为N时,每N个事务,才会将binlog写入磁盘。。当sync_binlog为1时,则表示每次commit,都将binlog 写入磁盘。来看一个比较完整的流程图吧:
 图片
图片
14.undo log 是什么?它有什么用
undo log 叫做回滚日志,用于记录数据被修改前的信息。它跟redo log重做日志所记录的相反,重做日志记录数据被修改后的信息。undo log主要记录的是数据的逻辑变化,为了在发生错误时回滚之前的操作,需要将之前的操作都记录下来,这样发生错误时才可以回滚。15. 说说Redo log的记录方式
redo log的大小是固定。它采用循环写的方式记录,当写到结尾时,会回到开头循环写日志。如下图(图片来源网络):
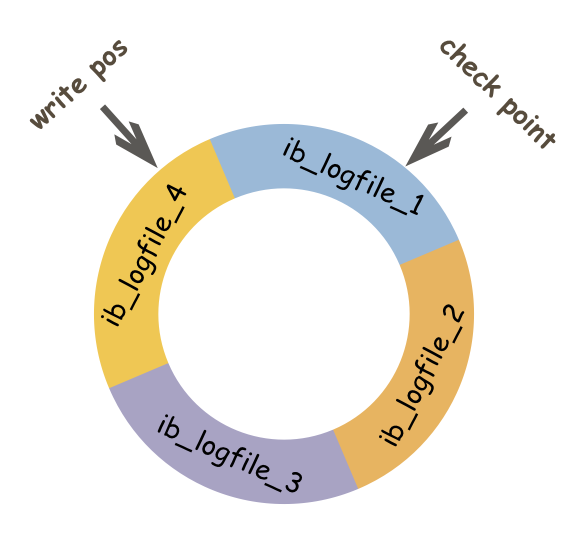 redo log 循环写入
redo log 循环写入
redo log buffer(内存中)是由首尾相连的四个文件组成的,它们分别是:ib_logfile_1、ib_logfile_2、ib_logfile_3、ib_logfile_4。
write pos表示当前写入记录位置(写入磁盘的数据页的逻辑序列位置)check point表示刷盘(写入磁盘)后对应的位置。write pos到check point之间的部分用来记录新日志,也就是留给新记录的空间。check point到write pos之间是待刷盘的记录,如果不刷盘会被新记录覆盖。有了 redo log,当数据库发生宕机重启后,可通过 redo log将未落盘的数据(check point之后的数据)恢复,保证已经提交的事务记录不会丢失,这种能力称为crash-safe。
随机阅读
- 探索iPhonePlus系列的魅力——以a1524的iPhone6Plus为例
- 电脑网络连接错误678的解决方法(探寻网络错误678的原因和解决方案)
- 将电脑内存条改成U盘的详细教程(简单快速地将电脑内存条改装成U盘的方法)
- 三星卡刷XP教程(详细步骤教你如何在三星手机上刷入XP系统,享受原汁原味的XP体验)
- 揭秘各大品牌路由器默认用户名密码的安全问题(隐私保护在默认配置中的薄弱环节)
- 电脑星际战甲注册教程(让你在星际战甲中畅快享受战斗乐趣的详细指南)
- 抖音烟花特效电脑教程(让你的视频焕发夺目光彩,掌握抖音烟花特效制作的关键技巧)
- 掌握平板电脑4指操作技巧,高效利用设备(简单易学的平板电脑4指操作教程,助您成为高手)
- 电脑玩原神遇到的问题及解决方法(探索神奇世界,解决游戏中常见错误)
- KMS激活使用教程(详细步骤图解,一键激活系统)
- 电脑迷你世界注册教程(轻松注册,畅玩电脑迷你世界)
- OnePlus5手机(性能强劲,拍照出色,价格亲民,OnePlus5是你的不二选择)
- 51系统安装教程(详解51系统的安装步骤与技巧)
- 电脑时钟错误导致无法上网的解决方法(解决电脑时钟错误,顺利上网畅享互联网世界)
热门排行
- 电脑连接键盘驱动错误解决方法(解决电脑无法识别或使用键盘的问题)
- 主板接线安装教程(详细步骤指南让你轻松安装主板,打造个性化电脑体验)
- 惠普暗影精灵6新手教程(掌握惠普暗影精灵6,打造专业级游戏体验)
- 电脑手绘装修柜子教程(学习如何使用电脑手绘技巧来装修你的柜子,让家居更加个性化)
- 电脑修改吃鸡比例教程(快速提升游戏胜率,让你成为吃鸡王者)
- 解决电脑蓝牙启动数据错误的方法(排查和修复蓝牙启动数据错误的步骤)
- 如何扩大老式电脑的内存容量?(简单易懂的教程,让你的老电脑焕发新生!)
- 电脑开机错误00005(深入了解电脑开机错误00005,避免数据丢失和系统崩溃)
- 电脑更新CF错误代码的解决方法(掌握解决CF错误代码的技巧,让游戏畅快进行)
- 电脑链接错误代码651的解决办法(遇到错误代码651时,你需要知道的关键信息)