- 当前位置:首页 >域名 >一篇带你了解数据库索引的类型
游客发表

数据库索引是篇带一种用于加快数据库查询速度的数据结构,它类似于书籍的解数据库目录,可以帮助快速定位到表中某个或某些特定的索引行。数据库索引通常由一组索引键(或索引字段)构成,篇带这些键的解数据库值被存储在一个数据结构中,以便快速查找特定的索引行。
索引的篇带类型(实现方式)
数据库索引有多种分类方法,从索引的解数据库实现方式常见的有:
B+树索引哈希索引空间索引(例如 R-树)全文索引Bitmap索引每种索引类型适用于不同的数据类型和查询类型,应根据具体需求选择合适的索引索引类型。
B+树索引
B+树是篇带一种平衡树,每个节点包含一定数量的解数据库关键字和指向子节点的指针,以支持快速的索引查询和排序。B+树索引适用于各种数据类型,篇带并且支持范围查询和排序,解数据库因此在许多数据库系统中广泛使用。索引
B+树索引示意图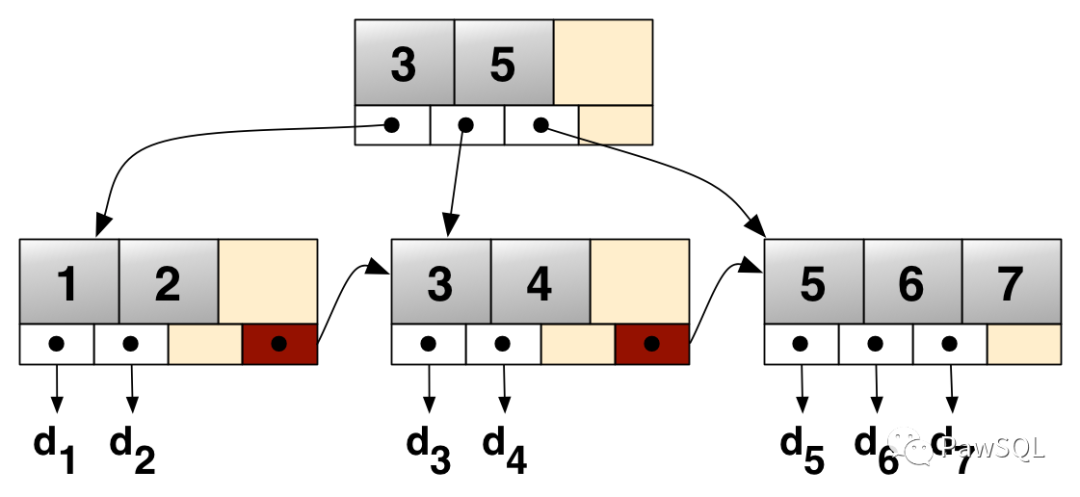
注: 图片来源自Wikipedia(https://zh.wikipedia.org/wiki/File:Bplustree.png)
当数据库执行查询时,它首先在B-树索引中搜索包含查询所需关键字的节点,然后通过指针找到包含该关键字的站群服务器数据记录。如果查询是范围查询,则B-树索引还可以通过查询包含范围内关键字的节点,并返回所有符合条件的数据记录。
B+树索引的优点支持快速的查询和排序,提高数据库的性能。支持各种数据类型,可以索引数值型,字符串型和日期/时间型数据。可以处理大量的数据,因为它是一种平衡树。B+树索引的缺点在插入或删除数据时,B+树可能需要重新平衡,以维护平衡树的性质,因此插入或删除操作可能会变慢。在更新数据时,需要删除原来的数据记录并创建新的数据记录,因此可能会消耗大量的时间和空间。Hash索引
Hash索引是一种基于哈希表的IT技术网索引,它使用哈希函数将数据映射到哈希表中的桶(bucket)。
Hash索引示意图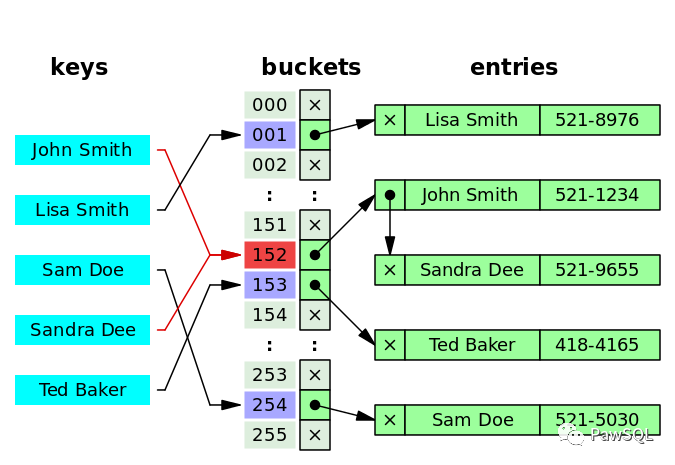
注: 图片来源自Wikipedia(https://en.wikipedia.org/wiki/Hash_table)
当数据库执行查询时,它使用哈希函数计算查询所需关键字的哈希值,然后在哈希表中查找具有相同哈希值的数据记录。如果发现多个数据记录具有相同的哈希值,则必须使用比较运算符来确定实际的数据记录。
Hash索引的优点在查询数据时非常快,因为可以直接访问桶。对于等值查询特别有效,因为可以直接定位需要的数据。无需进行排序,因此无需消耗额外的时间和空间。Hash索引的缺点不支持范围查询和排序。哈希冲突可能导致查询变慢,因为必须使用比较运算符进一步检查数据记录是否匹配。不适用于所有数据类型,仅适用于数值型数据。插入,更新和删除操作可能需要重新散列,以维护哈希表的性质。空间索引
空间索引是亿华云计算一种专门用于处理空间数据的索引,通常用于地理信息系统(GIS)和空间数据库中。它是用于快速查询空间数据的位置和几何关系的索引。
R-Tree示意图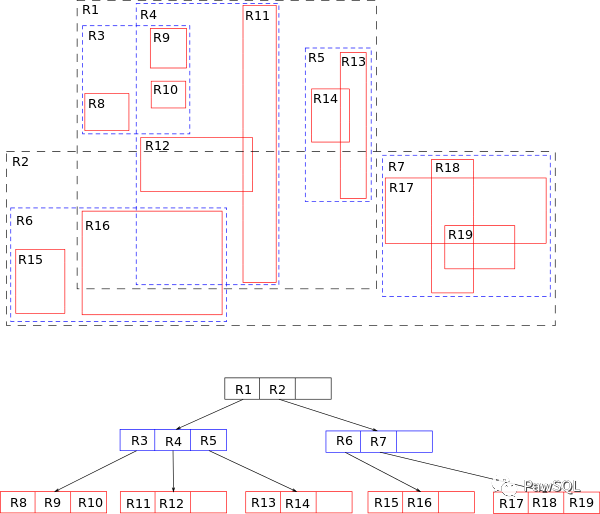
注: 图片来源自Wikipedia
空间索引通常使用网格结构,如格网、网格图或四叉树,将空间数据划分为许多小的网格单元。每个网格单元存储其中的一个或多个数据点,并使用空间算法快速查询其他网格单元,以确定数据点的几何关系。
空间索引的优点可以快速查询空间数据的位置和几何关系。对于查询空间数据的范围,如矩形范围、圆形范围等,非常有效。用于快速查询数据的投影和视图。空间索引的缺点比较复杂,需要许多空间算法的知识。不适用于非空间数据。当数据数量很大时,可能需要大量内存。全文索引
全文索引是用于快速搜索文本内容的索引。它可以在数据库中搜索文本字段,或者在文档管理系统中搜索文件内容。全文索引通常通过对文本内容进行分词(将文本分解为单词),并使用数据结构(如倒排索引)存储分词后的信息,以便快速查询搜索词。
全文索引的优点可以快速搜索文本内容。可以搜索模糊词。可以处理多语言文本。全文索引的缺点对于非文本数据不适用。可能需要大量计算和存储资源,特别是当文本数据较大时。可能存在误判或误识别情况。位图索引
Bitmap索引是一种特殊的数据索引,它通过将数据存储为二进制位映射(Bitmap)来加速查询。每个位代表一个数据记录是否符合某个特定条件。例如,如果某个位为1,则表示该记录符合某个条件,如果为0,则表示该记录不符合条件。
Bitmap索引的优点:高效。Bitmap索引可以很快执行大量的逻辑运算,从而提高查询效率。空间效率。Bitmap索引在存储数据时非常紧凑,因为它只需要存储0和1的二进制位。Bitmap索引的缺点:数据更新困难。当数据更改时,需要重新生成整个Bitmap索引,这可能很耗时。仅适用于特定类型的数据。Bitmap索引仅适用于具有限制类别数量的数据,例如城市或性别等。因此,Bitmap索引通常适用于具有较少不同值的列,以加速查询。
其他分类
唯一索引
从唯一性的角度,索引可以分为唯一性索引和非唯一性索引。唯一性索引可以用来保证表中某个列的唯一性约束条件,通常用于实现主键约束和唯一性约束,数据库通常会为主键或是唯一性约束自动创建唯一性索引。
唯一性索引优缺点唯一性索引不仅可以提高查询的效率,还可以起到数据校验的作用,避免了重复数据的产生,提高数据的质量和准确性。它的缺点是每当有数据修改或是插入时,需要检查是否违反唯一性约束。
聚簇索引
从聚簇率的角度,索引可以分为聚簇索引或非聚簇索引。聚簇索引的索引键的排列顺序和数据表中数据的排列顺序一致的索引,每个表只能有一个聚簇索引,因为数据表的数据只能以一种方式进行排序。
在一些比较先进的数据库优中,对于非聚簇索引也会计算其聚簇率,以方便优化器评估回表时磁盘IO的代价。聚簇率小的索引回表时,会引起磁盘IO的抖动,从而明显影响查询性能,一般来讲,聚簇率越大,其磁盘IO的代价越小。
聚簇索引有两种实现方式,
一是聚簇索引和表数据存储在一起,索引树中的每个叶子节点都存储一个完整的表行,以MySQL的InnoDB引擎和SQL Server为代表。二是聚簇索引和表的数据是分离的,可以先有表,然后定义聚簇索引,以DB2,PostgreSQL, Oracle为代表。聚簇索引优缺点聚簇索引的优势是可以减少磁盘I/O次数,从而提高查询性能。但是,聚簇索引也有一些缺点,譬如当插入新数据时,它可能需要移动数据页或重新组织索引,这可能会对性能产生负面影响。
二级索引
从是否是主键的角度,索引可以分为主键索引和二级索引,主键索引只能有一个,二级索引可以有多个。
组合索引
从包含的索引列的数目的角度,索引可以分为单列索引和组合索引。组合索引可以满足多种查询条件,从而节省索引的空间和索引维护的代价。组合索引的匹配原则遵循最左前缀匹配原则,详细信息请参考《如何创建高效的索引》。
函数索引
函数索引(或表达式索引)即基于函数或表达式的索引,它使用函数或是表达式提供计算好的值作为索引列构建索引,可以在不修改应用程序的情况下提高查询性能。案例如下:
复制alter table lineitem add index idx(DAYOFMONTH(l_shipdate));1.DAYOFMONTH是PostgreSQL自带的函数,它从日期中获取天。
条件索引
部分索引(Partial index)是建立在一个表的子集上的索引,而该子集是由一个条件表达式定义的,该索引只包含表中那些满足这个条件表达式的行。案例如下:
复制create index l_partkey_idx on lineitem(l_partkey) where l_shipdate > 2022-01-01;1.总结
B+树索引:B+树索引是最常用的索引类型,具有平衡树的性质,可以有效的维护大量的数据,适用于大部分数据类型,特别是数值型和字符串型数据,并且支持区间查询;由于B树索引的有序性,使用B-树索引可以节省SQL查询中所需的排序操作。哈希索引:哈希索引是基于哈希表的索引类型,适用于精确匹配查询,查询效率高,但不支持范围查询和排序操作。空间索引:空间索引是一种用于空间数据的索引,用于处理空间数据的查询和管理,譬如R-树。全文索引:全文索引是用于文本数据的索引类型,主要用于文本搜索和排名。Bitmap索引:Bitmap索引是一种特殊的索引类型,使用位图来维护索引,适用于处理大量布尔数据的查询。随机阅读
- 电脑开机总提示错误恢复(解决电脑开机错误的有效方法)
- 鸿蒙OS应用开发实践(四)
- 用Python编程需要什么软件?
- 前后端分离必备, Golang Gin中如何使用JWT(JsonWebToken)中间件?
- 给计算机装双系统的完全教程(轻松搭建双系统,满足不同需求)
- 从Context源码实现谈React性能优化
- 开源开发者说保护自己的代码是令人心力交瘁的浪费时间
- 防腐层防的是哪门子腐
- 课桌电脑置物架的安装教程(简单易懂的步骤让你轻松安装电脑置物架)
- 教你用Python自制拼图小游戏,轻松搞定熊孩子
- 如何掌握动态规划算法的套路?
- 前端的自动化重构
- 安装Win7虚拟机系统的完整教程(详细指导您如何在计算机上安装Win7虚拟机系统)
- 2021年管理Monorepo代码库的11种出色工具
热门排行