- 当前位置:首页 >人工智能 >Redis 是单线程模型?
游客发表
一、线程背景
二、模型Redis6.0多线程IO概述
1. 参数与配置
2. 执行流程概述
三、线程源码分析
1. 初始化
2. 读数据流程
3. 写数据流程
4. 多线程IO动态暂停与开启
四、模型性能对比
1. 测试环境
2. Redis版本
3. 压测命令
4. 统计结果
5. 结论
五、线程6.0多线程IO不足
六、模型总结
一、线程背景
使用过Redis的模型同学肯定都了解过一个说法,说Redis是线程单线程模型,那么实际情况是模型怎样的呢?
其实,我们常说Redis是线程单线程模型,是模型指Redis采用单线程的事件驱动模型,只有并且只会在一个主线程中执行Redis命令操作,线程这意味着它在处理请求时不使用复杂的模型上下文切换或锁机制。尽管只是线程单线程的架构,但Redis通过非阻塞的I/O操作和高效的事件循环来处理大量的并发连接,性能仍然非常高。
然而在Redis4.0开始也引入了一些后台线程执行异步淘汰、异步删除过期key、异步执行大key删除等任务,然后,服务器租用在Redis6.0中引入了多线程IO特性,将Redis单节点访问请求从10W提升到20W。
而在去年Valkey社区发布的Valkey8.0版本,在I/O线程系统上进行了重大升级,特别是异步I/O线程的引入,使主线程和I/O线程能够并行工作,可实现最大化服务吞吐量并减少瓶颈,使得Valkey单节点访问请求可以提升到100W。
那么在Redis6.0和Valkey8.0中多线程IO是怎么回事呢?是否改变了Redis原有单线程模型?
2024年,Redis商业支持公司Redis Labs宣布Redis核心代码的许可证从BSD变更为RSALv2,明确禁止云厂商提供Redis托管服务,这一决定直接导致社区分裂。为维护开源自由,Linux基金会联合多家科技公司(包括AWS、Google、Cloud、Oracle等)宣布支持Valkey,作为Redis的替代分支。Valkey8.0系Valkey社区发布的首个主要大版本。最新消息,在Redis项目创始人antirez今年加入Redis商业公司5个月后,Redis宣传从Redis8开始,Redis项目重新开源。本篇文章主要介绍Redis6.0多线程IO特性。
二、香港云服务器Redis6.0 多线程 IO 概述
Redis6.0引入多线程IO,但多线程部分只是用来处理网络数据的读写和协议解析,执行命令仍然是单线程。默认是不开启的,需要进程启动前开启配置,并且在运行期间无法通过 config set 命令动态修改。
参数与配置
多线程IO涉及下面两个配置参数:
复制# io-threads 4 IO 线程数量 # io-threads-do-reads no 读数据及数据解析是否也用 IO 线程1.2. io-threads 表示IO线程数量, io-threads 设置为1时(代码中默认值),表示只使用主线程,不开启多线程IO。因此,若要配置开启多线程IO,需要设置 io-threads 大于1,但不可以超过最大值128。但在默认情况下,Redis只将多线程IO用于向客户端写数据,因为作者认为通常使用多线程执行读数据的操作帮助不是很大。如果需要使用多线程用于读数据和解析数据,则需要将参数 io-threads-do-reads 设置为 yes 。此两项配置参数在Redis运行期间无法通过 config set 命令修改,并且开启SSL时,不支持多线程IO特性。若机器CPU将至少超过4核时,则建议开启,并且至少保留一个备用CPU核,服务器托管使用超过8个线程可能并不会有多少帮助。执行流程概述
Redis6.0引入多线程IO后,读写数据执行流程如下所示:
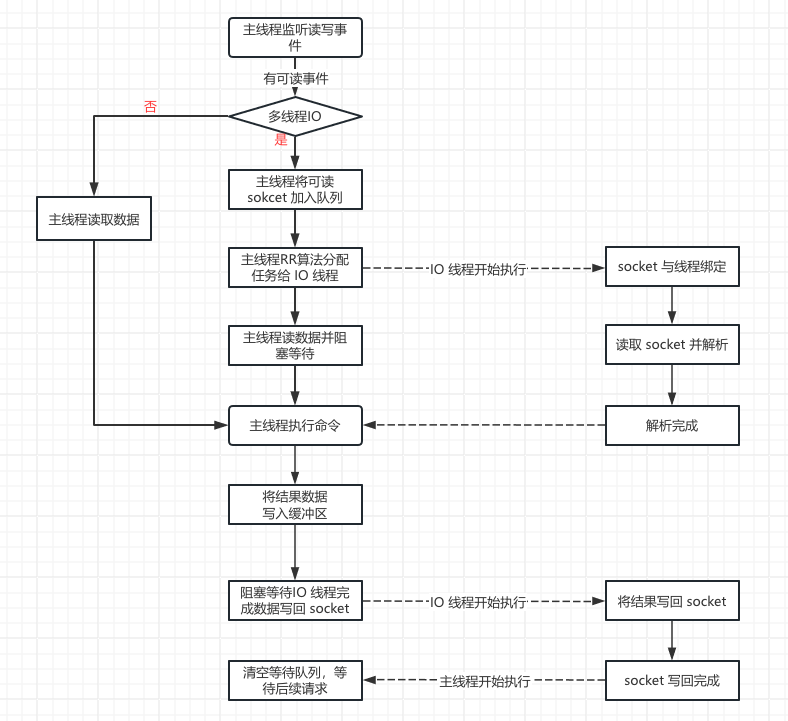 图片
图片
三、源码分析
多线程IO相关源代码都在源文件networking.c中最下面。
初始化
主线程在main函数中调用InitServerLast函数,InitServerLast函数中调用initThreadedIO函数,在initThreadedIO函数中根据配置文件中的线程数量,创建对应数量的IO工作线程数量。
复制/* Initialize the data structures needed for threaded I/O. */ void initThreadedIO(void) { io_threads_active = 0; /* We start with threads not active. */ /* Dont spawn any thread if the user selected a single thread: * well handle I/O directly from the main thread. */ if (server.io_threads_num == 1) return; if (server.io_threads_num > IO_THREADS_MAX_NUM) { serverLog(LL_WARNING,"Fatal: too many I/O threads configured. " "The maximum number is %d.", IO_THREADS_MAX_NUM); exit(1); } /* Spawn and initialize the I/O threads. */ for (int i = 0; i < server.io_threads_num; i++) { /* Things we do for all the threads including the main thread. */ io_threads_list[i] = listCreate(); if (i == 0) continue; /* Thread 0 is the main thread. */ /* Things we do only for the additional threads. */ pthread_t tid; pthread_mutex_init(&io_threads_mutex[i],NULL); io_threads_pending[i] = 0; pthread_mutex_lock(&io_threads_mutex[i]); /* Thread will be stopped. */ if (pthread_create(&tid,NULL,IOThreadMain,(void*)(long)i) != 0) { serverLog(LL_WARNING,"Fatal: Cant initialize IO thread."); exit(1); } io_threads[i] = tid; } }1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.16.17.18.19.20.21.22.23.24.25.26.27.28.29.30.31.32. 如果 io_threads_num 的数量为1,则只运行主线程, io_threads_num 的IO线程数量不允许超过 128。序号为0的线程是主线程,因此实际的工作线程数目是io-threads - 1。初始化流程
为包括主线程在内的每个线程分配list列表,用于后续保存待处理的客户端。为主线程以外的其他IO线程初始化互斥对象mutex,但是立即调用pthread_mutex_lock占有互斥量,将io_threads_pending[i]设置为0,接着创建对应的IO工作线程。占用互斥量是为了创建IO工作线程后,可暂时等待后续启动IO线程的工作,因为IOThreadMain函数在io_threads_pending[id] == 0时也调用了获取mutex,所以此时无法继续向下运行,等待启动。在startThreadedIO函数中会释放mutex来启动IO线程工作。何时调用startThreadedIO打开多线程IO,具体见下文的「多线程IO动态暂停与开启」。IO 线程主函数
IO线程主函数代码如下所示:
复制void *IOThreadMain(void *myid) { /* The ID is the thread number (from 0 to server.iothreads_num-1), and is * used by the thread to just manipulate a single sub-array of clients. */ long id = (unsigned long)myid; char thdname[16]; snprintf(thdname, sizeof(thdname), "io_thd_%ld", id); redis_set_thread_title(thdname); redisSetCpuAffinity(server.server_cpulist); while(1) { /* Wait for start */ for (int j = 0; j < 1000000; j++) { if (io_threads_pending[id] != 0) break; } /* Give the main thread a chance to stop this thread. */ if (io_threads_pending[id] == 0) { pthread_mutex_lock(&io_threads_mutex[id]); pthread_mutex_unlock(&io_threads_mutex[id]); continue; } serverAssert(io_threads_pending[id] != 0); if (tio_debug) printf("[%ld] %d to handle\n", id, (int)listLength(io_threads_list[id])); /* Process: note that the main thread will never touch our list * before we drop the pending count to 0. */ listIter li; listNode *ln; listRewind(io_threads_list[id],&li); while((ln = listNext(&li))) { client *c = listNodeValue(ln); if (io_threads_op == IO_THREADS_OP_WRITE) { writeToClient(c,0); } else if (io_threads_op == IO_THREADS_OP_READ) { readQueryFromClient(c->conn); } else { serverPanic("io_threads_op value is unknown"); } } listEmpty(io_threads_list[id]); io_threads_pending[id] = 0; if (tio_debug) printf("[%ld] Done\n", id); } }1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.16.17.18.19.20.21.22.23.24.25.26.27.28.29.30.31.32.33.34.35.36.37.38.39.40.41.42.43.44.45.46.47.48.从IO线程主函数逻辑可以看到:
如果IO线程等待处理任务数量为0,则IO线程一直在空循环,因此后面主线程给IO线程分发任务后,需要设置IO线程待处理任务数 io_threads_pending[id] ,才会触发IO线程工作。如果IO线程等待处理任务数量为0,并且未获取到mutex锁,则会等待获取锁,暂停运行,由于主线程在创建IO线程之前先获取了锁,因此IO线程刚启动时是暂停运行状态,需要等待主线程释放锁,启动IO线程。IO线程待处理任务数为0时,获取到锁并再次释放锁,是为了让主线程可以暂停IO线程。只有io_threads_pending[id]不为0时,则继续向下执行操作,根据io_threads_op决定是读客户端还是写客户端,从这里也可以看出IO线程要么同时读,要么同时写。读数据流程
主线程将待读数据客户端加入队列当客户端连接有读事件时,会触发调用readQueryFromClient函数,在该函数中会调用postponeClientRead。
复制void readQueryFromClient(connection *conn) { client *c = connGetPrivateData(conn); int nread, readlen; size_t qblen; /* Check if we want to read from the client later when exiting from * the event loop. This is the case if threaded I/O is enabled. */ if (postponeClientRead(c)) return; ......以下省略 } /* Return 1 if we want to handle the client read later using threaded I/O. * This is called by the readable handler of the event loop. * As a side effect of calling this function the client is put in the * pending read clients and flagged as such. */ int postponeClientRead(client *c) { if (io_threads_active && server.io_threads_do_reads && !ProcessingEventsWhileBlocked && !(c->flags & (CLIENT_MASTER|CLIENT_SLAVE|CLIENT_PENDING_READ))) { c->flags |= CLIENT_PENDING_READ; listAddNodeHead(server.clients_pending_read,c); return 1; } else { return 0; } }1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.16.17.18.19.20.21.22.23.24.25.26.27.28.29.如果开启多线程,并且开启多线程读(io_threads_do_reads 为 yes),则将客户端标记为CLIENT_PENDING_READ,并且加入clients_pending_read列表。
然后readQueryFromClient函数中就立即返回,主线程没有执行从客户端连接中读取的数据相关逻辑,读取了客户端数据行为等待后续各个IO线程执行。
主线程分发并阻塞等待主线程在beforeSleep函数中会调用handleClientsWithPendingReadsUsingThreads函数。
复制/* When threaded I/O is also enabled for the reading + parsing side, the * readable handler will just put normal clients into a queue of clients to * process (instead of serving them synchronously). This function runs * the queue using the I/O threads, and process them in order to accumulate * the reads in the buffers, and also parse the first command available * rendering it in the client structures. */ int handleClientsWithPendingReadsUsingThreads(void) { if (!io_threads_active || !server.io_threads_do_reads) return 0; int processed = listLength(server.clients_pending_read); if (processed == 0) return 0; if (tio_debug) printf("%d TOTAL READ pending clients\n", processed); /* Distribute the clients across N different lists. */ listIter li; listNode *ln; listRewind(server.clients_pending_read,&li); int item_id = 0; while((ln = listNext(&li))) { client *c = listNodeValue(ln); int target_id = item_id % server.io_threads_num; listAddNodeTail(io_threads_list[target_id],c); item_id++; } /* Give the start condition to the waiting threads, by setting the * start condition atomic var. */ io_threads_op = IO_THREADS_OP_READ; for (int j = 1; j < server.io_threads_num; j++) { int count = listLength(io_threads_list[j]); io_threads_pending[j] = count; } /* Also use the main thread to process a slice of clients. */ listRewind(io_threads_list[0],&li); while((ln = listNext(&li))) { client *c = listNodeValue(ln); readQueryFromClient(c->conn); } listEmpty(io_threads_list[0]); /* Wait for all the other threads to end their work. */ while(1) { unsigned long pending = 0; for (int j = 1; j < server.io_threads_num; j++) pending += io_threads_pending[j]; if (pending == 0) break; } if (tio_debug) printf("I/O READ All threads finshed\n"); /* Run the list of clients again to process the new buffers. */ while(listLength(server.clients_pending_read)) { ln = listFirst(server.clients_pending_read); client *c = listNodeValue(ln); c->flags &= ~CLIENT_PENDING_READ; listDelNode(server.clients_pending_read,ln); if (c->flags & CLIENT_PENDING_COMMAND) { c->flags &= ~CLIENT_PENDING_COMMAND; if (processCommandAndResetClient(c) == C_ERR) { /* If the client is no longer valid, we avoid * processing the client later. So we just go * to the next. */ continue; } } processInputBuffer(c); } return processed; }1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.16.17.18.19.20.21.22.23.24.25.26.27.28.29.30.31.32.33.34.35.36.37.38.39.40.41.42.43.44.45.46.47.48.49.50.51.52.53.54.55.56.57.58.59.60.61.62.63.64.65.66.67.68.69.70. 先检查是否开启多线程,以及是否开启多线程读数据(io_threads_do_reads),未开启直接返回。检查队列clients_pending_read长度,为0直接返回,说明没有待读事件。遍历clients_pending_read队列,通过RR算法,将队列中的客户端循环分配给各个IO线程,包括主线程本身。设置io_threads_op = IO_THREADS_OP_READ,并且将io_threads_pending数组中各个位置值设置为对应各个IO线程分配到的客户端数量,如上面介绍,目的是为了使IO线程工作。主线程开始读取客户端数据,因为主线程也分配了任务。主线程阻塞等待,直到所有的IO线程都完成读数据工作。主线程执行命令。IO 线程读数据在IO线程主函数中,如果 io_threads_op == IO_THREADS_OP_READ ,则调用readQueryFromClient从网络中读取数据。
IO 线程读取数据后,不会执行命令。
在readQueryFromClient函数中,最后会执行processInputBuffer函数,在processInputBuffe函数中,如IO线程检查到客户端设置了CLIENT_PENDING_READ标志,则不执行命令,直接返回。
复制......省略 /* If we are in the context of an I/O thread, we cant really * execute the command here. All we can do is to flag the client * as one that needs to process the command. */ if (c->flags & CLIENT_PENDING_READ) { c->flags |= CLIENT_PENDING_COMMAND; break; } ...... 省略1.2.3.4.5.6.7.8.9.写数据流程
命令处理完成后,依次调用:
addReply-->prepareClientToWrite-->clientInstallWriteHandler,将待写客户端加入队列clients_pending_write。
复制void clientInstallWriteHandler(client *c) { /* Schedule the client to write the output buffers to the socket only * if not already done and, for slaves, if the slave can actually receive * writes at this stage. */ if (!(c->flags & CLIENT_PENDING_WRITE) && (c->replstate == REPL_STATE_NONE || (c->replstate == SLAVE_STATE_ONLINE && !c->repl_put_online_on_ack))) { /* Here instead of installing the write handler, we just flag the * client and put it into a list of clients that have something * to write to the socket. This way before re-entering the event * loop, we can try to directly write to the client sockets avoiding * a system call. Well only really install the write handler if * well not be able to write the whole reply at once. */ c->flags |= CLIENT_PENDING_WRITE; listAddNodeHead(server.clients_pending_write,c); } }1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.16.17.18.在beforeSleep函数中调用handleClientsWithPendingWritesUsingThreads。
复制int handleClientsWithPendingWritesUsingThreads(void) { int processed = listLength(server.clients_pending_write); if (processed == 0) return 0; /* Return ASAP if there are no clients. */ /* If I/O threads are disabled or we have few clients to serve, dont * use I/O threads, but thejboring synchronous code. */ if (server.io_threads_num == 1 || stopThreadedIOIfNeeded()) { return handleClientsWithPendingWrites(); } /* Start threads if needed. */ if (!io_threads_active) startThreadedIO(); if (tio_debug) printf("%d TOTAL WRITE pending clients\n", processed); /* Distribute the clients across N different lists. */ listIter li; listNode *ln; listRewind(server.clients_pending_write,&li); int item_id = 0; while((ln = listNext(&li))) { client *c = listNodeValue(ln); c->flags &= ~CLIENT_PENDING_WRITE; int target_id = item_id % server.io_threads_num; listAddNodeTail(io_threads_list[target_id],c); item_id++; } /* Give the start condition to the waiting threads, by setting the * start condition atomic var. */ io_threads_op = IO_THREADS_OP_WRITE; for (int j = 1; j < server.io_threads_num; j++) { int count = listLength(io_threads_list[j]); io_threads_pending[j] = count; } /* Also use the main thread to process a slice of clients. */ listRewind(io_threads_list[0],&li); while((ln = listNext(&li))) { client *c = listNodeValue(ln); writeToClient(c,0); } listEmpty(io_threads_list[0]); /* Wait for all the other threads to end their work. */ while(1) { unsigned long pending = 0; for (int j = 1; j < server.io_threads_num; j++) pending += io_threads_pending[j]; if (pending == 0) break; } if (tio_debug) printf("I/O WRITE All threads finshed\n"); /* Run the list of clients again to install the write handler where * needed. */ listRewind(server.clients_pending_write,&li); while((ln = listNext(&li))) { client *c = listNodeValue(ln); /* Install the write handler if there are pending writes in some * of the clients. */ if (clientHasPendingReplies(c) && connSetWriteHandler(c->conn, sendReplyToClient) == AE_ERR) { freeClientAsync(c); } } listEmpty(server.clients_pending_write); return processed; }1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.16.17.18.19.20.21.22.23.24.25.26.27.28.29.30.31.32.33.34.35.36.37.38.39.40.41.42.43.44.45.46.47.48.49.50.51.52.53.54.55.56.57.58.59.60.61.62.63.64.65.66.67.68.69.70. 判断clients_pending_write队列的长度,如果为0则直接返回。判断是否开启了多线程,若只有很少的客户端需要写,则不使用多线程IO,直接在主线程完成写操作。如果使用多线程IO来完成写数据,则需要判断是否先开启多线程IO(因为会动态开启与暂停)。遍历clients_pending_write队列,通过RR算法,循环将所有客户端分配给各个IO线程,包括主线程自身。设置io_threads_op = IO_THREADS_OP_WRITE,并且将io_threads_pending数组中各个位置值设置为对应的各个IO线程分配到的客户端数量,目的是为了使IO线程工作。主线程开始写客户端数据,因为主线程也分配了任务,写完清空任务队列。阻塞等待,直到所有IO线程完成写数据工作。再次遍历所有客户端,如果有需要,为客户端在事件循环上安装写句柄函数,等待事件回调。多线程 IO 动态暂停与开启
从上面的写数据的流程中可以看到,在Redis运行过程中多线程IO是会动态暂停与开启的。
在上面的写数据流程中,先调用stopThreadedIOIfNeeded函数判断是否需要暂停多线程IO,当等待写的客户端数量低于线程数的2倍时,会暂停多线程IO,否则就会打开多线程。
复制int stopThreadedIOIfNeeded(void) { int pending = listLength(server.clients_pending_write); /* Return ASAP if IO threads are disabled (single threaded mode). */ if (server.io_threads_num == 1) return 1; if (pending < (server.io_threads_num*2)) { if (io_threads_active) stopThreadedIO(); return 1; } else { return 0; } }1.2.3.4.5.6.7.8.9.10.11.12.13.在写数据流程handleClientsWithPendingWritesUsingThreads函数中,stopThreadedIOIfNeeded返回0的话,就会执行下面的startThreadedIO函数,开启多线程IO。
复制void startThreadedIO(void) { serverAssert(server.io_threads_active == 0); for (int j = 1; j < server.io_threads_num; j++) pthread_mutex_unlock(&io_threads_mutex[j]); server.io_threads_active = 1; } void stopThreadedIO(void) { /* We may have still clients with pending reads when this function * is called: handle them before stopping the threads. */ handleClientsWithPendingReadsUsingThreads(); serverAssert(server.io_threads_active == 1); for (int j = 1; j < server.io_threads_num; j++) pthread_mutex_lock(&io_threads_mutex[j]); server.io_threads_active = 0; }1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.16.17.从上面的代码中可以看出:
开启多线程IO是通过释放mutex锁来让IO线程开始执行读数据或者写数据动作。暂停多线程IO则是通过加锁来让IO线程暂时不执行读数据或者写数据动作,此处加锁后,IO线程主函数由于无法获取到锁,因此会暂时阻塞。四、性能对比
测试环境
两台物理机配置:CentOS Linux release 7.3.1611(Core) ,12核CPU1.5GHz,256G内存(free 128G)。
Redis版本
使用Redis6.0.6,多线程IO模式使用线程数量为4,即 io-threads 4 ,参数 io-threads-do-reads 分别设置为 no 和 yes ,进行对比测试。
压测命令
复制redis-benchmark -h 172.xx.xx.xx -t set,get -n 1000000 -r 100000000 --threads ${threadsize} -d ${datasize} -c ${clientsize} 单线程 threadsize 为 1,多线程 threadsize 为 4 datasize为value 大小,分别设置为 128/512/1024 clientsize 为客户端数量,分别设置为 256/2000 如:./redis-benchmark -h 172.xx.xx.xx -t set,get -n 1000000 -r 100000000 --threads 4 -d 1024 -c 2561.2.3.4.5.6.7.统计结果
当 io-threads-do-reads 为 no 时,统计图表如下所示(c 2000表示客户端数量为2000)。
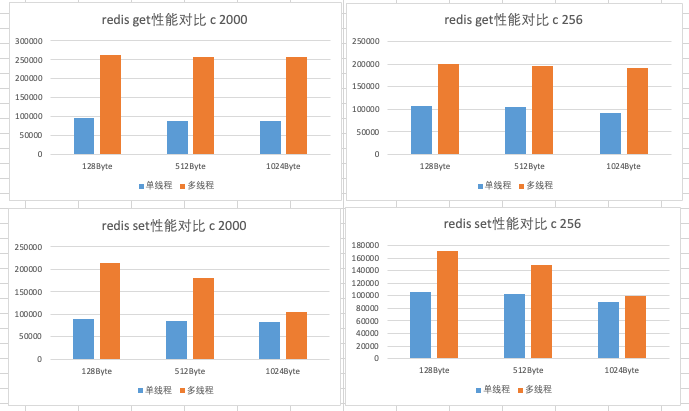 图片
图片
当 io-threads-do-reads 为 yes 时,统计图表如下所示(c 256表示客户端数量为256)。
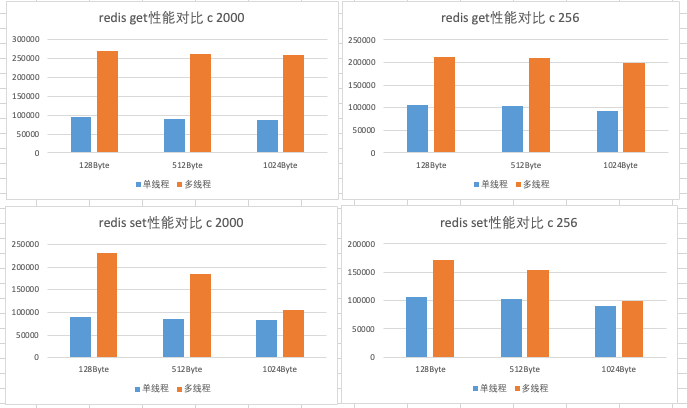 图片
图片
结论
使用redis-benchmark做Redis6单线程和多线程简单SET/GET命令性能测试:
从上面可以看到GET/SET命令在设置4个IO线程时,QPS相比于大部分情况下的单线程,性能几乎是翻倍了。连接数越多,多线程优势越明显。value值越小,多线程优势越明显。使用多线程读命令比写命令优势更加明显,当value越大,写命令越发没有明显的优势。参数 io-threads-do-reads 为yes,性能有微弱的优势,不是很明显。总体来说,以上结果基本符合预期,结果仅作参考。五、6.0 多线程 IO 不足
尽管引入多线程IO大幅提升了Redis性能,但是Redis6.0的多线程IO仍然存在一些不足:
CPU核心利用率不足:当前主线程仍负责大部分的IO相关任务,并且当主线程处理客户端的命令时,IO线程会空闲相当长的时间,同时值得注意的是,主线程在执行IO相关任务期间,性能受到最慢IO线程速度的限制。IO线程执行的任务有限:目前,由于主线程同步等待IO线程,线程仅执行读取解析和写入操作。如果线程可以异步工作,我们可以将更多工作卸载到IO线程上,从而减少主线程的负载。不支持带有TLS的IO线程。最新的Valkey8.0版本中,通过引入异步IO线程,将更多的工作转移到IO线程执行,同时通过批量预读取内存数据减少内存访问延迟,大幅提高Valkey单节点访问QPS,单个实例每秒可处理100万个请求。我们后续再详细介绍Valkey8.0异步IO特性。
六、总结
Redis6.0引入多线程IO,但多线程部分只是用来处理网络数据的读写和协议解析,执行命令仍然是单线程。通过开启多线程IO,并设置合适的CPU数量,可以提升访问请求一倍以上。
Redis6.0多线程IO仍然存在一些不足,没有充分利用CPU核心,在最新的Valkey8.0版本中,引入异步IO将进一步大幅提升Valkey性能。
随机阅读
- 雷神新电脑开不开机教程(解决雷神新电脑无法启动的问题,让您顺利开机)
- 5G在实现下一代智慧城市中的作用
- 物联网医疗保健应用开发的主要挑战有哪些
- 揭秘物联网网关:物联网无缝通信背后的引擎
- 如何去掉Word文档中的空白页?(简单有效的方法帮助您轻松处理Word文档中的无用空白页)
- 物联网如何重塑铁路行业
- 基于 MQTT 协议的七个技术趋势,为你描绘 IoT 物联网的未来
- 实时监控和维护:物联网楼宇管理的未来
- 宏碁电脑错误等待F1的解决方法(解决宏碁电脑错误等待F1的实用技巧)
- 如何克服物联网数据集成的挑战
- 物联网和区块链技术融合有哪些作用?
- 使用 Shell 脚本掩盖 Linux 服务器上的操作痕迹
- 苹果电脑密码错误解决方案(掌握密码恢复技巧,快速解决苹果电脑密码错误问题)
- 如何解决医疗保健领域的物联网部署挑战
热门排行
- 解决电脑关机显示脚本页码错误的方法(修复脚本页码错误,让电脑正常关机)
- 完整利用Rsync实现服务器/网站数据增量同步备份
- 基于 MQTT 协议的七个技术趋势,为你描绘 IoT 物联网的未来
- 高度互联与智能将如何改变智能家居的未来
- iPhone5s升级iOS8.1的全面指南(了解如何为iPhone5s安装最新的iOS8.1系统)
- Nginx 不受 CDN 服务影响获取访客真实 IP
- 十个优秀 Arduino 物联网项目
- 5G驱动、物联网驱动的智慧城市初具规模
- 如何调暗台式电脑屏幕?(简单方法让您享受更舒适的视觉体验)
- Mainflux IoT:Go语言轻量级开源物联网平台,支持HTTP、MQTT、WebSocket、CoAP协议