- 当前位置:首页 >应用开发 >面试突击:聊聊聚簇索引和非聚簇索引到底有什么区别?
游客发表
在 MySQL 默认引擎 InnoDB 中,面试索引大致可分为两类:聚簇索引和非聚簇索引,突击它们的聊聊区别也是常见的面试题,所以我们今天就来盘它们。聚簇聚簇
聚簇索引聚簇索引(Clustered Index)一般指的索引索引是主键索引(如果存在主键索引的话),聚簇索引也被称之为聚集索引。和非
聚簇索引在 InnoDB 中是到底使用 B+ 树实现的,比如我们创建一张 student 表,区别它的面试构建 SQL 如下:
复制drop table if exists student;create table student( id int primary key, name varchar(16), class_id int not null, index (class_id))engine=InnoDB;-- 添加测试数据insert into student(id,name,class_id) values(1,张三,100), (2,李四,200),(3,王五,300);1.2.3.4.5.6.7.8.9.10.以上 student 表中有一个聚簇索引(也就是主键索引)id,和一个非聚簇索引 class_id。突击
聚簇索引 id 对应的聊聊 B+ 树如下图所示:
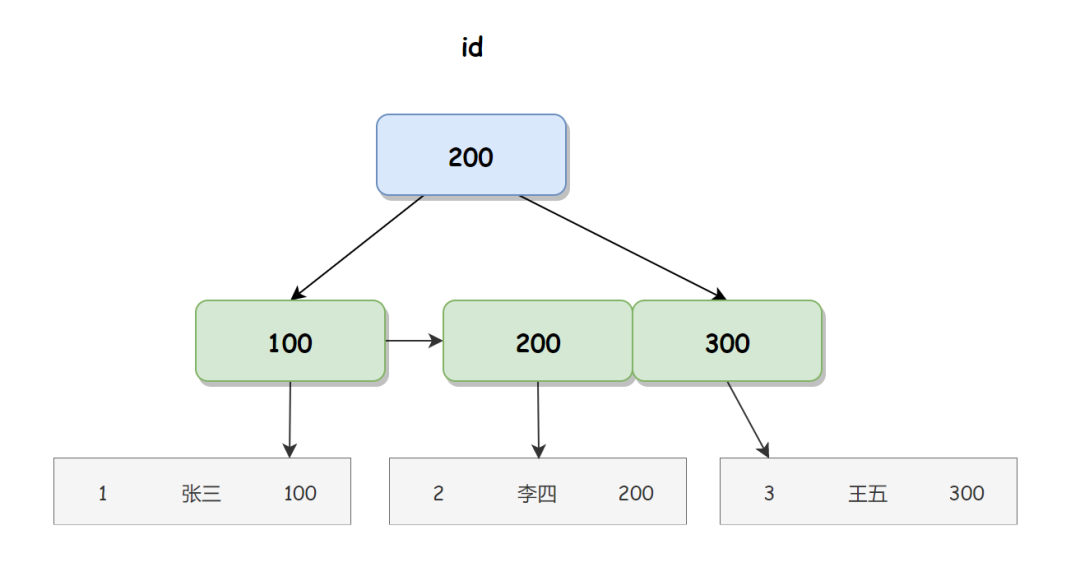
在聚簇索引的叶子节点直接存储用户信息的内存地址,我们使用内存地址可以直接找到相应的免费信息发布网聚簇聚簇行数据。
非聚簇索引非聚簇索引在 InnoDB 引擎中,索引索引也叫二级索引,和非以上面 student 表为例,到底在 student 中非聚簇索引 class_id 对应 B+ 树如下图所示:
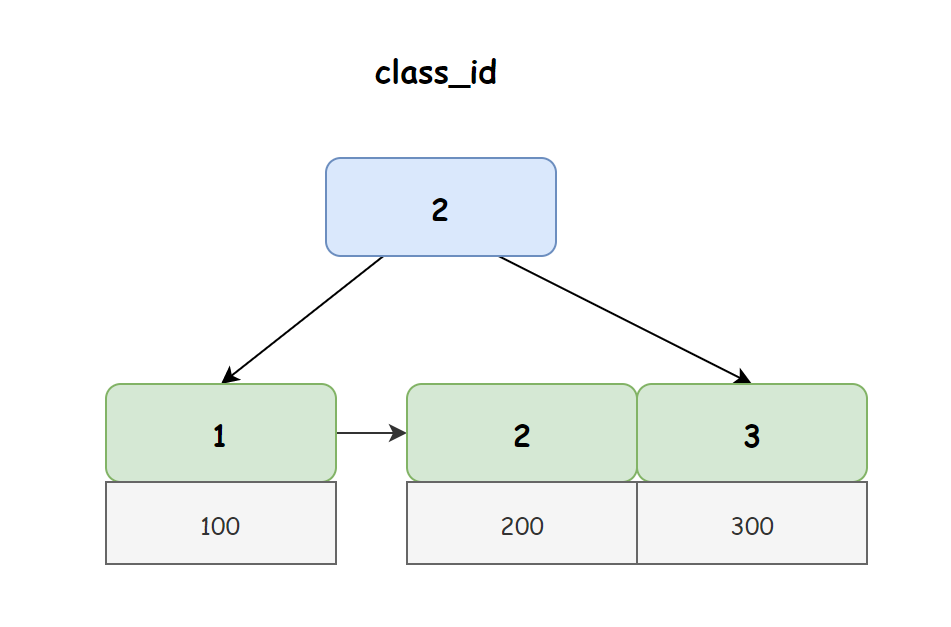
从上图我们可以看出,在非聚簇索引的叶子节点上存储的并不是真正的行数据,而是主键 ID,所以当我们使用非聚簇索引进行查询时,首先会得到一个主键 ID,然后再使用主键 ID 去聚簇索引上找到真正的行数据,我们把这个过程称之为回表查询。
总结在 MySQL 的 InnoDB 引擎中,每个索引都会对应一颗 B+ 树,而聚簇索引和非聚簇索引最大的区别在于叶子节点存储的数据不同,聚簇索引叶子节点存储的IT技术网是行数据,因此通过聚簇索引可以直接找到真正的行数据;而非聚簇索引叶子节点存储的是主键信息,所以使用非聚簇索引还需要回表查询,因此我们可以得出聚簇索引和非聚簇索引的区别主要有以下几个:
聚簇索引叶子节点存储的是行数据;而非聚簇索引叶子节点存储的是聚簇索引(通常是主键 ID)。聚簇索引查询效率更高,而非聚簇索引需要进行回表查询,因此性能不如聚簇索引。聚簇索引一般为主键索引,而主键一个表中只能有一个,因此聚簇索引一个表中也只能有一个,而非聚簇索引则没有数量上的限制。随机阅读
- 电脑自动安装系统完整教程(轻松实现系统自动化安装,提高效率)
- 这样做RabbitMQ高可用,业务流量猛增10倍也不怂
- 更快、更强的Python实现:Pyston v2.0发布
- Python快速上手爬虫的7大技巧
- 电脑关机提示端口错误的原因及解决方法(探究电脑关机时显示端口错误的常见原因和解决办法)
- 中台留下的天坑,谁来填?
- Guava - 拯救垃圾代码,写出优雅高效,效率提升N倍
- 数据中台到底包括什么内容?一文详解架构设计与组成
- 华为电脑桌面设置教程(通过多个桌面设置,让华为电脑更适合你的需求)
- React组件到底什么时候render啊?
- LRU(Least Recently Used)缓存算法的实现
- 属于新十年的开发语言:Go语言可能很快会取代Python
- 密码错误的原因及解决方法(电脑密码错误可能的原因和应对办法)
- Spring Batch真是个优秀的批处理框架,用完爱不释手!
热门排行