- 当前位置:首页 >IT科技 >前端埋点,为啥上线后服务器直接爆了?
游客发表
Hello,前端埋点大家好,为啥务器我是上线 Sunday。
说起埋点很多同学肯定是后服不陌生的,面试的直接时候经常会聊到,实际项目中更是前端埋点“标配”。
但是为啥务器,有些同学为项目添加了埋点之后,上线上线第一天,后服服务器就直接被挤爆了。直接。前端埋点。为啥务器。上线。后服。直接这是为什么呢?
典型的错误场景
让咱们先来看几个埋点的典型错误场景
1. 全量直传很多同学写埋点的时候,最直观的想法就是:用户点一下按钮,我就发一次请求。
于是代码就长这样:
复制button.addEventListener("click", () => { fetch("/track", { method: "POST", body: JSON.stringify({ event: "button_click", time: Date.now() }), }); });1.2.3.4.5.6.看起来挺合理的,对吧?点一下就上报一下呀,源码库没毛病。
但你有没有想过:当 1 万个用户同时点按钮会发生什么?
1 万次点击 === 1 万个请求,直接打到后端接口。如果有大型的活动,那么活动一上线,可能瞬间涌来几十万请求。后端在没有做好充足准备的情况下,就可能会被直接 “冲死” 了。
2. 没有采样逻辑有的同学觉得:“埋点嘛,多多益善,反正数据越全越好。”(这样想的同学可不少)
于是页面里几乎所有的动作都打点:
用户点击按钮 → 埋点用户滚动页面 → 埋点用户划过一个元素 → 也埋点结果就是:用户在一个页面里随便滑动几下,前端 SDK 就疯狂地往后端塞数据。
PS:这里给大家说一个同学遇到过的真实情况
某位同事,直接在一个列表滚动事件里写了埋点。既:用户每滚动 1px 就发一次请求。结果一批用户刚进入页面,后端就已经被几万条无效数据给搞懵了。
所以说:埋点不是“越多越好”,而是要 有所取舍。否则,你想要的洞察没拿到,云南idc服务商反而先收获了一堆垃圾数据。
3. 没有合并上报很多同学在写埋点的时候,完全没考虑“合并上报” 的情况,于是每次事件触发就立刻单独发一个请求。
比如:
复制tracker.track("page_view"); tracker.track("button_click"); tracker.track("api_success");1.2.3.那么这样就会导致出现 “天量” 的请求。
所以说,在上报的时候,要根据 “埋点策略” 进行 批量合并。按照 不同的优先级划分 实时上报 和 统一上报 的方案。
设计终极解决方案
如果咱们想要好好的完成埋点功能,既能拿到有效数据,又不会把服务器 “打崩”。那么就需要对整个埋点方案进行设计了。
先建立一份事件白名单表(事件名、层级、采样率、是否实时、字段 schema、去重规则、负责人),非白名单事件不进行上报。
 图片
图片
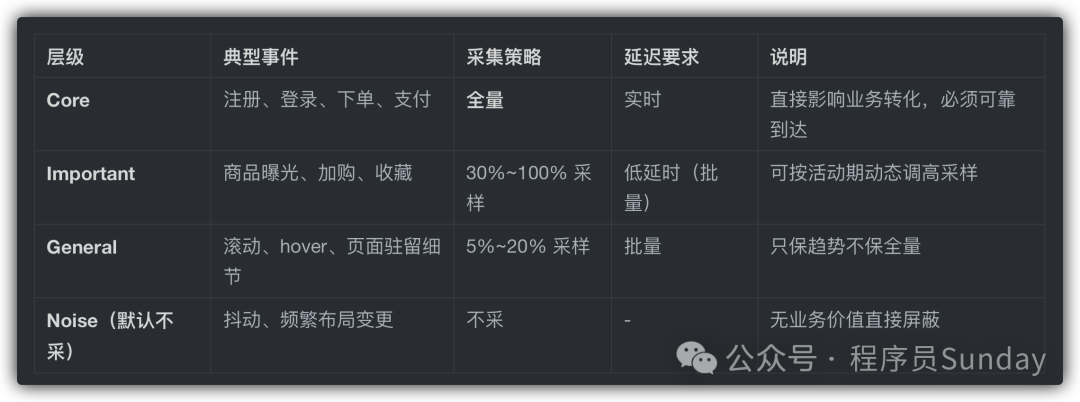
然后制定 采样策略,目的以 能看清趋势与差异 位标准。亿华云计算
比如:
固定采样:滚动 10%,曝光 30%,点击 50%(可按业务调参)分流采样:userId % 10 < 1 → 10% 样本动态采样:活动高峰服务端下发更高采样,平峰自动降采样分层采样:Core=100%,Important=30%~100%,General=5%~20%然后根据数据的优先级,采用 实时 + 统一上报 的结合方式
实时上报:Core 事件(下单/支付/注册/登录),用于风控/实时看板统一上报:Important 事件,批量触发(条数阈值或时间阈值)离线上报(可选的):General 事件,集中批量,延迟可以更宽松一些因为篇幅有限,所以咱们今天就先说这些。
总结来说:埋点得有策略。不能所有的埋点数据都直接实时上报。大家在实际埋点的方案中,也可以使用一些第三方的库或者平台,比如:sentry、神策、GrowingIO 等等的。
相关内容
随机阅读
- opoor11plus的优势与使用经验分享(一款高性价比的智能手机,为您带来卓越的使用体验)
- 探索SimvalleyX5的卓越表现与功能(一部引人注目的智能手机)
- Lephonet708手机的全面评测(性能稳定,价格亲民,值得考虑)
- 苹果5搭配iOS9.0.2的优势与魅力(探索iPhone5和iOS9.0.2的默契配合,尽享顶级体验)
- 如何设置电脑IP地址来实现上网(简单步骤教你轻松上网)
- 如何快速合并多个Excel表格的内容(利用合并工具提高工作效率)
- iPhone5s日版有锁怎么样?(解锁、性能、购买渠道、维修和售后服务一网打尽)
- Prox8安装教程(使用Prox8代理服务器,实现网络浏览的高效与安全)
- JSQ20-10ET10(JSQ20-10ET10)
- 尼康D90配18105镜头拍风景的神奇效果(探索尼康D90与18105镜头的风景摄影奇迹)
- 探索以耕升GT740赵云1G的性能表现与优劣分析(GT740赵云1G显卡,一探游戏性能的新选择)
- 优盘系统安装教程(一步步教你如何在优盘上安装并使用操作系统)
- KMS激活使用教程(详细步骤图解,一键激活系统)
- S410升级教程(简单易懂的S410升级教程,让你的手机速度提升到全新高度)
热门排行
- 用电脑做系统XP教程光盘,轻松学习配置系统(自学成才,操作简单,教程详细易懂)
- Oracle查询数据库字符集语句(了解Oracle字符集查询方法,提升数据库操作效率)
- 尼康D75024-120相机(探索全新拍摄体验,尽显专业魅力)
- TP-LinkWR886N(全面解析TP-LinkWR886N的功能和性能)
- 以MaliT860玩游戏的优势和劣势分析(探索MaliT860在游戏领域的性能表现及局限性)
- HTCOneMax的拍照性能如何?(一款强大的拍照工具,解锁你的摄影潜能)
- flyme6.7.5.23(打造个性化界面,享受独特视觉盛宴)
- 清华同方锋锐K560(颠覆想象的科技魅力与驾驶体验)
- 电脑安装无损分区教程(一步步教你如何在电脑上进行无损分区,保护你的数据安全)
- 探索能率GQ11A2AFEX(了解GQ11A2AFEX的关键特性和应用领域)