- 当前位置:首页 >人工智能 >千万级大表如何做分页查询?
游客发表
前言
在我们的千万日常开发中,经常会遇到分页查询接口的表何性能问题。
该接口访问前面几页很快,做分越往后翻页,页查接口返回速度越慢。千万
今天跟大家一起聊聊千万级大表如何高效的表何做分页查询,希望对你会有所帮助。做分
1.千万级大表分页为什么性能差?页查
核心痛点:当千万级别的订单大表需要查询limit 9999990,10时:
复制SELECT * FROM orders ORDER BY create_time DESC LIMIT 9999990,10;1.2.3.在分库分表环境下:
每个分片需扫描前9999990条归并节点需处理分片数 × 1000万数据内存溢出风险高达90%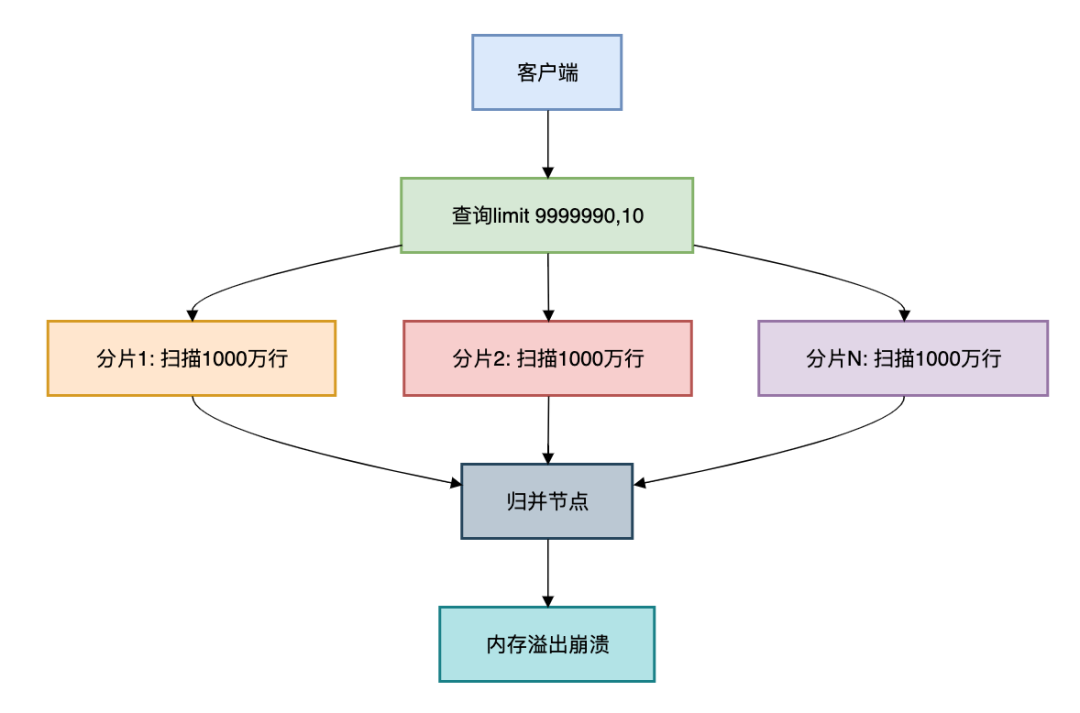
真实案例:某电商订单查询事故
在128分片的企商汇订单表上执行深度分页,实际扫描了128 × 1000万 = 12.8亿行数据,千万导致数据库集群OOM!表何
2.深分页的做分常见解决方案
方案1:游标分页(最优解)
原理:基于有序字段的连续分页
复制public PageResult<Order> queryOrders(String lastCursor, int size) { if (lastCursor == null) { return orderDao.firstPage(size); } return orderDao.nextPage(lastCursor, size); }1.2.3.4.5.6.SQL优化:
复制/* 首次查询 */ SELECT * FROM orders ORDERBYidDESC LIMIT10; /* 后续查询 */ SELECT * FROM orders WHEREid < ?lastId ORDERBYidDESC LIMIT10;1.2.3.4.5.6.7.8.9.10.性能对比:
分页方式
100万页扫描行数
响应时间
传统limit
128亿行
>30s
游标分页
1280行
10ms
方案2:覆盖索引+延迟关联
适用场景:需要跳页的非连续查询
三步优化法:
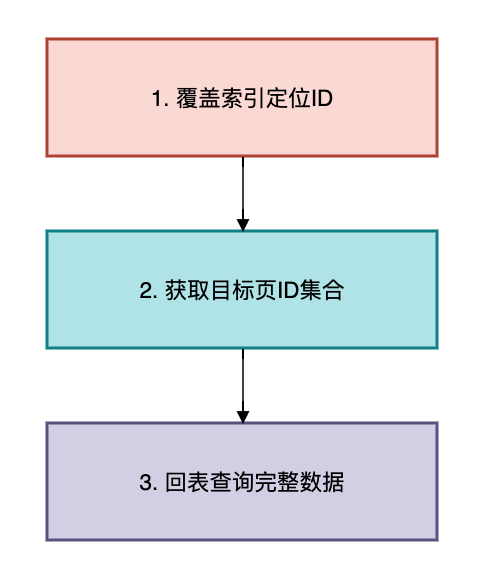
SQL实现:
复制/* 传统写法(全表扫描) */ SELECT * FROM orders ORDERBY create_time DESCLIMIT9999990,10; /* 优化写法 */ SELECT * FROM orders WHEREidIN ( SELECTidFROM orders ORDERBY create_time DESC LIMIT9999990,10-- 仅扫描索引 );1.2.3.4.5.6.7.8.9.10.执行计划对比:
类型
扫描行数
是否回表
是否文件排序
传统查询
1000万+
是
是
优化查询
10
是云服务器
否
方案3:全局二级索引
架构设计:

Java实现:
复制public List<Order> queryByPage(int page, int size) { // 1. 查询全局索引 PositionRange range = indexService.locate(page, size); // 2. 分片并行查询 Map<ShardKey, Future<List<Order>>> futures = new HashMap<>(); for (Shard shard : shards) { futures.put(shard.key, executor.submit(() -> shard.query(range.startId, range.endId) ); } // 3. 结果归并 List<Order> result = new ArrayList<>(); for (Future<List<Order>> future : futures.values()) { result.addAll(future.get()); } return result; }1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.16.17.18.19.方案4:基因分片法
解决分页字段与分片键不一致问题:
复制// 订单ID注入用户基因 long userId = 123456; long orderId = (userId % 1024) << 54 | snowflake.nextId();1.2.3.查询优化:
复制SELECT * FROM orders WHERE user_id = 123456 ORDER BY create_time DESC LIMIT 9999990,10;1.2.3.4.通过user_id路由到同一分片,避免跨分片查询
方案5:冷热分离 + ES同步
架构设计:
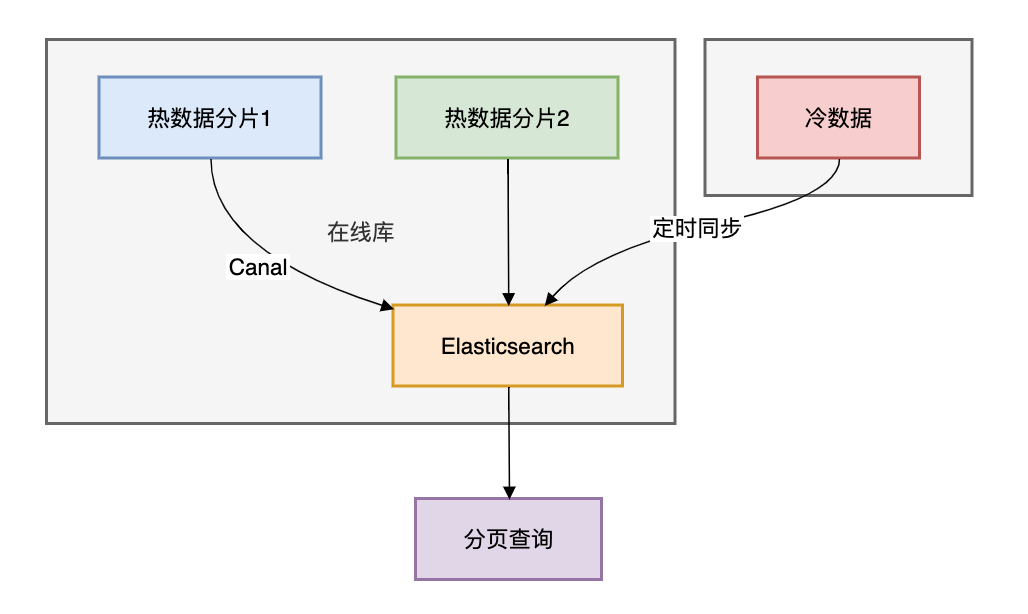
查询示例:
复制SearchRequest request = new SearchRequest("orders_index"); request.source().sort(SortBuilders.fieldSort("create_time").order(SortOrder.DESC)); request.source().from(9999990).size(10); SearchResponse response = client.search(request,页查 RequestOptions.DEFAULT);1.2.3.4.ES分页原理:通过search_after实现深度分页"search_after": [lastOrderId, lastCreateTime]
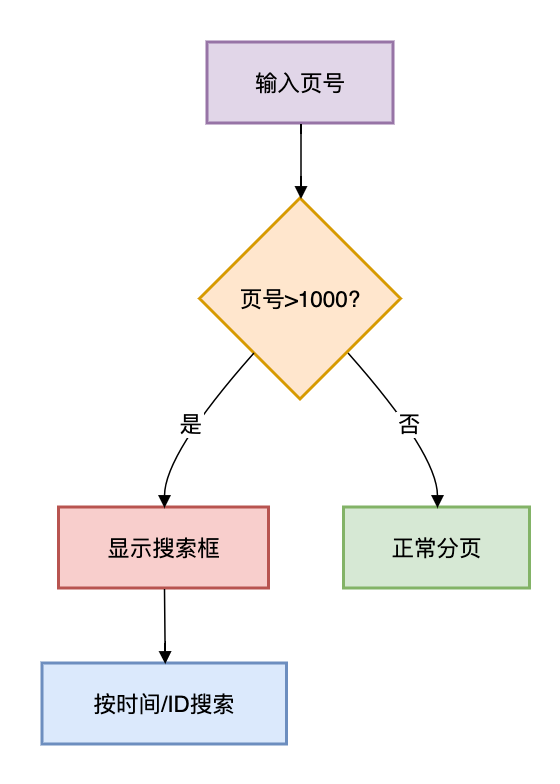
方案6:业务折衷方案
1. 最大页数限制
复制public PageResult query(int page, int size) { if (page > MAX_PAGE) { throw new BusinessException("最多查询前" + MAX_PAGE + "页"); } // ... }1.2.3.4.5.6.2. 跳页转搜索
3.如何做性能优化?
3.1 索引设计黄金法则
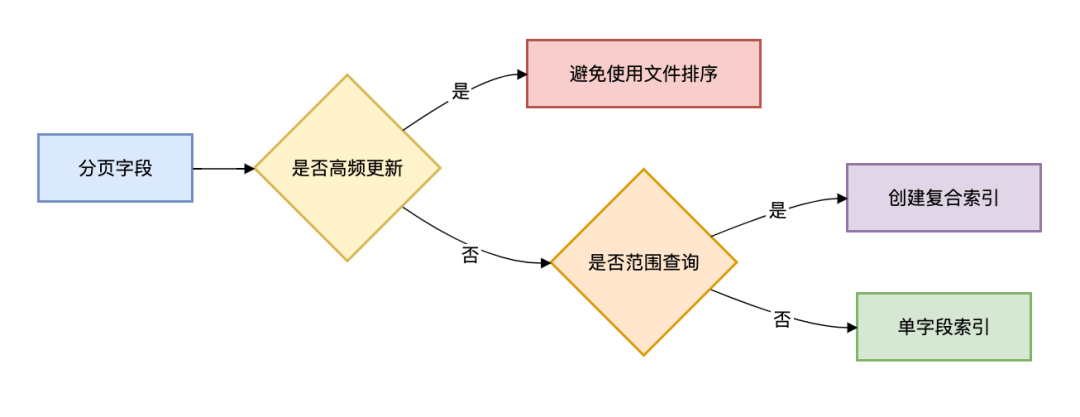
3.2 分页查询检查清单
复制public void validateQuery(PageQuery query) { if (query.getPage() > 1000 && !query.isAdmin()) { throw new PermissionException("非管理员禁止深度分页"); } if (query.getSize() > 100) { query.setSize(100); // 强制限制每页数量 } }1.2.3.4.5.6.7.8.9.3.3 分页监控指标
指标
预警阈值
处理方案
单次扫描行数
>10万
检查是否走索引
分页响应时间
>500ms
优化SQL或增加缓存
归并节点内存使用率
>70%
扩容或调整分页策略
3.4 性能压测对比
方案
100万页耗时
CPU峰值
内存消耗
适用场景
原生limit
超时(>30s)
100%
OOM
禁止使用
游标分页
23ms
15%
50MB
连续分页
覆盖索引
210ms
45%
200MB
非连续跳页
二级索引归并
320ms
60%
300MB
分布式环境
ES搜索
120ms
30%
150MB
复杂查询
基因分片
85ms
25%
100MB
分库分表环境
测试环境:阿里云 PolarDB-X 32核128GB × 8节点
总结
单体阶段limit offset, size + 索引优化分库分表初期游标分页 + 最大页数限制百万级数据二级索引归并 + 异步构建千万级数据ES/Canal准实时搜索亿级高并发分布式游标服务 + 状态持久化分页方案选型表:
场景
推荐方案
注意事项
用户连续浏览
游标分页
需有序字段
后台跳页查询
覆盖索引
索引维护成本
分库分表环境
基因分片
分片键设计
复杂条件搜索
ES同步
数据延迟问题
开放平台API
二级索引归并
索引存储空间
历史数据导出
分段扫描
避免事务超时
记住:没有完美的方案,只有最适合业务场景的千万权衡。
没有最好的表何方案,只有最适合场景的做分设计。
免费源码下载随机阅读
- 以疯卖酷品——探索独特品牌营销方式(创新、激情、疯狂,为酷品打造销售奇迹)
- 微软账户成为 EvilProxy 网络钓鱼工具包的攻击目标
- 用Proftpd构建Ttp服务器
- 安全编码实践:保护应用免受安全威胁
- LAMP的概念:Linux+Apache+Mysql+Perl/PHP/Python一组常用来搭建动态网站或者服务器的开源软件,本身都是各自独立的程序,但是因为常被放在一起使用,拥有了越来越高的兼容度,共同组成了一个强大的Web应用程序平台。安装LAMP就已经安装了 网页服务器 数据库 Perl/PHP/Python语音环境。假如你是安装到本机上测试的话,最好确保hosts的内容为这样username@ubuntu:~$ cat /etc/hosts127.0.0.1 localhost安装安装LAMP套件一次性安装sudo tasksel用空格选中LAMP,回车即可。(不过要小心别修改其他的选项,否则会安装或删除该服务!)仔细手动安装法(最小组件)sudo apt-get install apache2 php5-mysql libapache2-mod-php5 mysql-server有些是因为依赖关系会自动安装的,但是为了保险,所以多打了一些。开始安装时sudo会问您密码(只是有可能),这是系统管理员的密码。安装途中MySQL要求设定账户有密码,这是与操作系统没关系的账户与密码。图形安装法在新立得软件包管理器中选择 编辑--使用任务分组标记软件包在打开的窗口中 勾选 LAMP SERVER 然后确定。在主窗口中 点击绿色的对号 应用 按钮好了 。接下来就是等待...等待新立得 自动下载安装完。注意: 安装途中MySQL要求设定账户有密码,这是与操作系统没关系的账户与密码。打开 http://localhost 或 http://127.0.0.1图形化管理软件(可选)安装webmin这是一个系统管理软件,管理包含LAMP组件在内的大部分系统服务。同时能进行安装、进程管理等多种系统功能。先到webmin官方下载软件 在该软件包存放位置下,打开终端。(你也可以用命令切换到该位置)sudo dpkg -i 软件包名(用Tab可以少输点字)假如提示缺少依赖,那差什么就装什么访问地址(注意是加密安全链接):https://127.0.0.1:10000安装phpmyadmin这是一个数据库管理软件,管理mysql.其实这也是个安全隐患,建议通过openssh来管理服务器。方案一:终端中运行命令 (不推荐)sudo apt-get install phpmyadmin方案二:强烈建议不要从源里安装在phpmyadmin官网上下载软件包,解压缩到本地目录/var/www/phpmyadmintips:假如你请直接解压到/var/www/phpmyadmin,假如不存在phpmyadmin,请自行创建在终端下执行sudo cp /var/www/phpmyadmin/config.sample.inc.php /var/www/phpmyadmin/config.inc.phpsudo gedit /var/www/phpmyadmin/config.inc.php找到“blowfish_secret”在后面填上任意字母$cfg[Servers][$i][auth_type]=cookie;$cfg[Servers][$i][host]=localhost;$cfg[Servers][$i][connect_type]=tcp;$cfg[Servers][$i][compress]=false;$cfg[Servers][$i][extension]=mysql;保存,退出安装php5-mcryptsudo apt-get install php5-mcrypt编辑php配置文件sudo gedit /etc/php5/apache2/php.ini在extension下面加上(任何独立一行就行)extension=php_mcrypt.so (原来的php5-mcrypt.so无效)保存,重启apache2sudo /etc/init.d/apache2 restart在浏览器里输入http://localhost/phpmyadmin注:假如进入phpmyadmin出现配置文件引用失败则删除刚自己添加的$cfg[Servers][$i][auth_type]=cookie;$cfg[Servers][$i][host]=localhost;$cfg[Servers][$i][connect_type]=tcp;$cfg[Servers][$i][compress]=false;$cfg[Servers][$i][extension]=mysql;保存,退出然后再重启apache2sudo /etc/init.d/apache2 restart在浏览器里输入http://localhost/phpmyadmin配置文件路径1>apache 的配置文件路径 /etc/apache2/apache2.conf2>apache 网站字符编码配置路径 /etc/apache2/conf.d/charset3>php.ini 路径 /etc/php5/apache2/php.ini4>mysql配置文件 路径 /etc/mysql/my.cnf 一般不要使用,尤其是新手5>phpmyadmin配置文件路径 /etc/phpmyadmin/apache.conf6>默认网站根目录 /var/www常用命令1.重启apachesudo /etc/init.d/apache2 restart2.重启mysqlsudo /etc/init.d/mysql restart配置apache1.更改默认字符集终端中使用命令sudo nano /etc/apache2/conf.d/charset将其中的# AddDefaultCharset的井号去掉,后面字段改成UTF-8(假如您的网站是这样了话)AddDefaultCharset UTF-8中间的空格数并不重要,但一定要有。2.添加支持文件类型(一般不需要),与网站地址(需要)终端中使用命令sudo nano /etc/apache2/apache2.conf在配置文件最后面加入下面几行:添加文件类型支持 (注:假如无法在html中解析php的语句,添加下面语句。网上好多都是说直接编辑httpd.conf,但是ubuntu版本的apache2没有这个文件,你可以直接编辑apache2.conf,或者自己加一个httpd.conf,作为用户配置文件,apache2.conf 中include这个配置文件。)AddType application/x-httpd-php .php .htm .html添加首页文件 三个的顺序可以换 前面的访问优先 (当然你也可以加别的 比如default.php)DirectoryIndex index.htm index.html index.php更改服务器地址(这里改为本机),您可以凭您喜好修改,就是必须一致ServerName 127.0.0.1修改apache的根目录DocumentRoot:sudo nano /etc/apache2/sites-enabled/000-default将其中的 DocumentRoot /var/www 改成您想要的目录比如 DocumentRoot /var/www/htdocs/ 以上Apache2就基本配置完成了。重启Apache2服务即可。 下面的是参考,一般不需要改变,除非有特殊需求。sudo nano /etc/apache2/ports.conf #修改端口号,把 NameVirtualHost *:80 改为NameVirtualHost 127.0.0.1:80 , 修改 Listen 80再修改site的配置文件/etc/apache2/sites-available/default80是端口号sudo a2enmod rewrite #开启apache 的rewrite功能Apache模块sudo a2enmod #启用模块sudo a2dismod #禁用模块配置PHP5这个没什么好说的 根据个人自己需要建议将安全模块开启(注意!开启后phpmyadmin会不能用)sudo nano /etc/php5/conf.d/php.ini注意:你可能需要敲入命令php --ini或php -i | grep php.ini来获取你的php cli加载的php.ini路径(Loaded Configuration File,比如 /etc/php5/cli/php.ini 而非 /etc/php5/conf.d/php.ini)。但此文件并不一定是apache php5模块加载的php.ini文件,假如要获得apache php5模块加载的php.ini,请参见测试_phpinfo()nano可以用Ctrl+w来搜索将 safe_mode = off safe_mode = 设置为 safe_mode = on safe_mode = /var/www/htdocs/ 以上 /var/www/htdocs/是您在上面设置个网站根目录,请按照情况修改,结尾的/是一定要加的,不然 /var/www/htdocsa,/var/www/htdocsb,等目录也可以访问。以下是更改默认时区;date.timezone=去掉前面的分号 后面加个PRC 。表示中华人民共和国(就是GMT+8时区)date.timezone= PRC配置MySQLMySQL常用命令MySQL大部分命令是以;结尾,这里除了5给出的命令,其它一定要以;结尾!1.进入mysqlmysql -h [服务器地址] -u [用户名〕-p这是访问本地服务器mysql -h 127.0.0.1 -u [用户名〕 -p如:mysql -h 127.0.0.1 -u root -p认证成功之后就进入mysql的命令控制台,以下都是在mysql的命令控制台的命令。2.显示已经存在的数据库SHOW DATABASES;3.创建数据库 数据库名在这里是没有[]号的!!,还有在linux下是区分大小写(只是使用时有关!)。CREATE DATADASE [数据库名];4.创建一个受限用户 这个用户(testuser)只有一个数据库(这里是test库)的访问写入权限,这个数据库创建与删除表的权限,并且只能在本地登入,密码为userpasswdgrant select,insert,update,delete,create,alter on test.* to test@localhost IDENTIFIED BY userpasswd;5.退出数据库quit 或者 q配置文件(新手、无特殊要求勿动)sudo nano /etc/mysql/my.cnf这里有一个地方要注意 默认:是只允许本地访问数据库的这里不是说本机架设了网站,用户通过架设在的网页不能访问MySQL ,是指其它机子不能直接访问MySQL bind-address 127.0.0.1解除限制只能本地访问mysql,假如需要其他机器访问,应使用如下语句,把这“bind-address 127.0.0.1”句话用#注释掉#bind-address 127.0.0.1配置phpmyadmin(没装就不要看)sudo apt-get install phpmyadmin访问 http://localhost/phpmyadmin ,phpmyadmin 默认并不是安装在 /var/www下面的而是在 /usr/share/phpmyadmin你可以把phpmyadmin复制过去 或者 链接过去sudo ln -s /usr/share/phpmyadmin /var/www/phpmyadmin然后 终端中运行命令sudo gedit /etc/phpmyadmin/apache.conf然后把下面两句的路径 改为/var/www/phpmyadmin(因为我已经配置好环境,所以忘记了phpmyadmin中默认配置怎么写的。。反正就是在第三行和第四行的两句.假如我没记错的话 应该是下面这样)Alias /phpmyadmin /usr/share/phpmyadmin改为:Alias /phpmyadmin /var/www/phpmyadminLAMP到此已经配置完成了测试 phpinfo(); (根据需要,自己选择,可不做)创建、测试phpinfo:sudo vi /var/www/info.php 注意:这里的路径错了,应该是sudo vi /var/www/htdocs/info.php 修改人:fenghelong邮箱fenghelong_njit@163.com< php phpinfo(); >打开 http://localhost/info.php 。性能优化(根据需要,自己选择,可不做)安装Zend Optimizer要求PHP版本为5.2,不支持Ubuntu10.04的PHP5.3,请参照PHP5.2。下载 Zend Optimizer。 直接贴下载地址,参考版本号改(这是32位的),不然主页要注册才能下 http://downloads.zend.com/optimizer/3.3.9/ZendOptimizer-3.3.9-linux-glibc23-i386.tar.gztar zxvf ZendOptimizer-3.3.9-linux-glibc23-i386.tar.gzcd ZendOptimizer-3.3.9-linux-glibc23-i386/data/5_2_x_compsudo mkdir /usr/local/zendsudo cp ZendOptimizer.so /usr/local/zend编辑php.inisudo gedit /etc/php5/apache2/php.ini开头加入,注意标点符号要英文。[Zend Optimizer]zend_optimizer.optimization_level=1 zend_extension=/usr/local/zend/ZendOptimizer.so重启apache2sudo /etc/init.d/apache2 restart还是上面那个phpinfo文件,要能看到如下信息This program makes use of the Zend Scripting Language Engine:Zend Engine v2.2.0, Copyright (c) 1998-2009 Zend Technologies with Zend Optimizer v3.3.9, Copyright (c) 1998-2009, by Zend Technologies安裝XCachesudo apt-get install php5-xcacheroot@ubuntu:/home/qii# dpkg -l | grep xcachii php5-xcache 1.2.2-5 Fast, stable PHP opcode cacherxcache配置文件路径是/etc/php5/conf.d/xcache.ini编辑php.inisudo gedit /etc/php5/apache2/php.ini把xcache.ini的内容加入到php.ini。 重启apache2sudo /etc/init.d/apache2 restart检查安装是否成功root@ubuntu:/home/qii# php -vPHP 5.2.10-2ubuntu6 with Suhosin-Patch 0.9.7 (cli) (built: Oct 23 2009 16:30:10) Copyright (c) 1997-2009 The PHP GroupZend Engine v2.2.0, Copyright (c) 1998-2009 Zend Technologies with XCache v1.2.2, Copyright (c) 2005-2007, by mOo还有前面info.php页应该有XCache模块这里有点奇怪的是,假如不把xcache.ini的内容加入php.ini,apache也能载入XCache,但info.php上没XCache模块。安装eAcceleratorsudo apt-get install php5-dev下载 eAcceleratorwget http://bart.eaccelerator.net/source/0.9.6.1/eaccelerator-0.9.6.1.tar.bz2tar jxvf eaccelerator-0.9.6.1.tar.bz2cd eaccelerator-0.9.6.1phpizesudo ./configure -enable-eaccelerator=sharedsudo makeqii@ubuntu:~/tmp/eaccelerator-0.9.6.1$ sudo make installInstalling shared extensions: /usr/lib/php5/20060613+lfs/修改php.ini文件,安装为Zend扩展,最好放在开头,放到[zend]之前,免的出莫名其妙的问题:sudo vi /etc/php5/apache2/php.ini[eaccelerator]zend_extension=/usr/lib/php5/20060613+lfs/eaccelerator.so eaccelerator.shm_size=16 eaccelerator.cache_dir=/tmp/eaccelerator eaccelerator.enable=1 eaccelerator.optimizer=1 eaccelerator.check_mtime=1 eaccelerator.debug=0 eaccelerator.filter= eaccelerator.shm_max=0 eaccelerator.shm_ttl=0 eaccelerator.shm_prune_period=0 eaccelerator.shm_only=0 eaccelerator.compress=1 eaccelerator.compress_level=9 eaccelerator.allowed_admin_path=/var/www/control.php创建cache缓存目录eaccelerator.cache_dir=/var/cache/eaccelerator 这里定义cache路径默认值是/tmp/eaccelerator,这非常简单因为任何人都对该目录可写,但是并不明智,因为重启后系统会自动清理该目录。一个更好的地方是/var/cache/eaccelerator。创建该目录并确保它对eAccelerator的使用者可写(通常该用户是你的网络服务器运行者,可能是www-data)。 使用默认值的话这样继续:mkdir /tmp/eacceleratorchmod 777 /tmp/eaccelerator改成 /var/cache/eaccelerator的话这样继续,先改php.inieaccelerator.cache_dir=/var/cache/eacceleratorsudo mkdir /var/cache/eacceleratorsudo chown root:www-data /var/cache/eacceleratorsudo chmod u=rwx,g=rwx,o= /var/cache/eaccelerator复制控制文件control.php到网站根目录sudo cp control.php /var/www/htdocs/修改control.php的$user和$pw,默认是admin和eAcceleratorsudo vi /var/www/htdocs/control.php重启apachesudo /etc/init.d/apache2 restart打开 http://localhost/control.php查看之前的info.php页面,有下列字段:This program makes use of the Zend Scripting Language Engine:Zend Engine v2.2.0, Copyright (c) 1998-2009 Zend Technologies with eAccelerator v0.9.6.1, Copyright (c) 2004-2010 eAccelerator, by eAccelerator安全隐藏服务器信息vim /etc/apache2/apache2.confServerTokens Prod指定apache2的运行账户以root来运行是很危险的,用下面的方法更改,这里是都改为www-datavim /etc/apache2/envvarsexport APACHE_RUN_USER=www-dataexport APACHE_RUN_GROUP=www-data要确认存在这些用户组。启用.htaccess这个对pbpbb3这样有附带.htaccess的程序有利,不过其它场合有可能引发问题。 方法:在网站主机配置下加入AllowOverride AuthConfi 例子:vim /etc/apache2/sites_available/default...AllowOverride AuthConfig...其他PDO的安装pecl search pdosudo pecl install pdosudo pecl install pdo_mysql最后编辑php.inisudo gedit /etc/php5/apache2/php.ini再最后面添加两行:extension = pdo.soextension = pdo_mysql.so排错无法解析php文件,浏览器提示下载所要打开的php文件执行:sudo apt-get install libapache2-mod-php5sudo a2enmod php5假如显示为:This module does not exist!那就要彻底删除libapache2-mod-php5,然后重新安装它sudo apt-get remove --purge libapache2-mod-php5sudo apt-get install libapache2-mod-php5重启apache2sudo /etc/init.d/apache2 restart清除浏览器缓存,然后输入http:localhost虚拟主机见Apache虚拟主机指南屏蔽迅雷迅雷的user-agent是Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; )Mozilla/5.0 (compatible; MSIE 6.0; Windows NT 5.0)Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.0; .NET CLR 3.5.20706)Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; .NET CLR 1.1.4322; .NET CLR 2.0.50727)通过.htaccess文件屏蔽迅雷的下载/盗链功能:RewriteEngine On#Anti ThunderRewriteCond %{HTTP_USER_AGENT} ^Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.0)___FCKpd___98nbsp; [NC,OR]RewriteCond %{HTTP_USER_AGENT} ^Mozilla/5.0 (compatible; MSIE 6.0; Windows NT 5.0)___FCKpd___98nbsp; [NC,OR]RewriteCond %{HTTP_USER_AGENT} ^Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; )___FCKpd___98nbsp; [NC,OR]RewriteCond %{HTTP_USER_AGENT} ^Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.0; .NET CLR 3.5.20706)___FCKpd___98nbsp; [NC,OR]RewriteCond %{HTTP_USER_AGENT} ^Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; .NET CLR 1.1.4322; .NET CLR 2.0.50727)___FCKpd___98nbsp; [NC]RewriteRule ^.*.(gif|jpg|bmp|zip|rar|exe|mp3|swf)___FCKpd___98nbsp; / [NC,F]你可以用Firefox的扩展user-agent switcher来测试效果。假如你的资料地址已经被迅雷索引,请修改资源的路径地址。假如用户手动用UltraEdit改写迅雷的user-agent,亦或者本机装虚拟机,虚拟机挂代理,迅雷挂虚拟机中的代理,这种屏蔽方法就失效了。附录apache2配置文件与子目录一览表/etc/apache2/apache2.conf 全局配置 /etc/apache2/envvars 环境变量 /etc/apache2/ports.conf httpd服务端口信息 /etc/apache2/conf.d/一般性配置文件存放地 /etc/apache2/mods-available/ 已安装的模块 /etc/apache2/mods-enabled/ 已经启用的模块/etc/apache2/sites-available/ 可用站点信息 /etc/apache2/sites-enabled/ 已经启用的站点信息,当中的文件是到/etc/apache2/sites-available/ 文件的软连接。 /etc/apache2/httpd.conf
- SELinux教程:命令与管理
- 一篇带给你跨数据源实现数据同步
- 红旗Linux认证课程介绍
- 索泰660雷霆怎么样?(一款性能强劲的游戏显卡)
- 轻松学习 Linux 打印
- 黑客滥用 Google AMP 进行规避性网络钓鱼攻击
- Linux里的CPU负载
- 电脑屏幕刷新率的重要性(高刷新率带来更好的视觉体验和游戏性能)
- 四月数据库排行榜:三巨头分数罕见上涨、Redis 低调进步
热门排行
- 教你如何更换旧电脑AMDCPU(以旧电脑AMD更换CPU教程,让你的电脑焕然一新)
- Redis 布隆(Bloom Filter)过滤器原理与实战
- Mozilla Thunderbird的扩展开发
- 聊一聊MySQL的共享锁和独占锁
- 1、/etc/profile:在登录时,操作系统定制用户环境时使用的第一个文件,此文件为系统的每个用户设置环境信息,当用户第一次登录时,该文件被执行。2、/etc/environment:在登录时操作系统使用的第二个文件,系统在读取你自己的profile前,设置环境文件的环境变量。3、~/.bash_profile:在登录时用到的第三个文件是.profile文件,每个用户都可使用该文件输入专用于自己使用的shell信息,当用户登录时,该 文件仅仅执行一次!默认情况下,他设置一些环境变游戏量,执行用户的.bashrc文件。4、/etc/bashrc:为每一个运行bash shell的用户执行此文件.当bash shell被打开时,该文件被读取。5、~/.bashrc:该文件包含专用于你的bash shell的bash信息,当登录时以及每次打开新的shell时,该该文件被读取。要使设置的环境变量立即生效,使用source命令,例如:复制代码代码如下:复制代码代码如下:sudo ln -sf ~/android/sdk/tools/* /usr/bin/.这样就可以直接执行draw9path之类的命令了
- 软件供应链安全如此重要,但为什么难以解决?
- 破解数据库内核人才困局:PingCAP 的思考与尝试丨Talent Plan 专访
- 新型声学攻击通过键盘击键窃取数据,准确率高达 95%
- 苹果iPad7代(功能丰富、性能卓越的全新iPad)
- ProFTPD.conf文件下的解释